
Article
Apache Airflow at Adyen: Our journey and challenges to achieve reliability at scale
By Natasha Shroff, Data Engineer; and Jorrick Sleijster, Data Platform Engineer.
In this blog post, we will share how we work towards reliability at scale. We answer the following questions that cover the challenges we have encountered on our journey:
Setting up a scalable multi-tenant Airflow setup
Preparing for the worst: Handling machine failures
Handling task priority
Maximizing user productivity
Apache Airflow at Adyen
Adyen is a financial technology platform providing end-to-end payments capabilities, financial products and data-driven insights to thousands of businesses around the world.
We started with payments, at a time when providers offered services based on a patchwork of systems built on outdated infrastructure… our ambition demanded more!
So, we set off to build a financial technology platform for the modern era, entirely in-house, from the ground up. Today, we provide our payment solution to leading businesses around the world, with billions in processed volumes.
As you can imagine, processing and storing thousands of payments per second requires a well-designed, reliable, and scalable system. While we love to build these complex systems and frameworks in-house, when it comes to data orchestration we trust Airflow to do the job.
The crux of reliability on our systems
Data coming from processing payments needs to be written to our data warehouse on time, and be as complete as possible. This data orchestration is crucial for scenarios such as an ongoing fraud attack from credit card fraudsters that needs to be stopped before more damage happens. If we don’t deliver the right data to our merchants, they’ll lack the insights that they need to make qualified business decisions like putting more fraud protection rules in place to prevent future attacks from happening.
Another example is detailed payment reports that our merchants download for their daily analysis. If these reports are not made available on time, merchants don’t have any insights as to how many payments they have received from which store, and how many of them were actually settled. A lack of these insights could mean that fraud attacks or payment errors go unnoticed, and can result in millions of lost income. For our merchants, this could have severe consequences such as losing their capital to produce new products and thus running the risk of having to close down their business.
These are some of the reasons we have more than 250 data professionals working in at least 40 different teams focused on product analytics or ML models.These teams own and monitor a staggering 600+ DAGs (Directed Acyclic Graph) in Airflow, with more than 10.000 tasks running on a regular basis — most of them hourly or daily. We use Spark and HDFS to accompany the Airflow orchestrator, see this blog about our Airflow setup for more information.
In the intro to this article, we highlighted some of the challenges we have faced on our journey, let’s explore them further in the next sections.
Challenge 1 — Setting up a scalable multi-tenant Airflow setup
One of our top priorities is ensuring our Airflow cluster stays available, reliable and secure at all times for all of our tenants. The tenants are our product teams producing value for our merchants with scheduled insights, predictions, ML training pipelines etc. At Adyen we run everything on-premise, meaning we administer the servers ourselves and don’t use any cloud for hosting our products. We also try to exclusively use open-source tools, hence Airflow fits right in.
Achieving high availability
To become highly-available, we set up our Airflow cluster such that it exists out of three celery workers, schedulers and web servers each. We have NGINX & Keepalived in front of each of the web servers. This will make sure the web traffic will always go to a webserver that is up and alive. To store the Airflow metadata, we use a highly-available PostgreSQL setup spread across three different servers. Running our setup on three different servers prevents our Airflow cluster from going down when one individual machine or rack becomes faulty. Currently, our Airflow setup is directly installed on the machines, but our next update will be to containerize our setup and fully migrate to Kubernetes.
Multi-tenant permission structure
To streamline our user access, we tuned the airflow permission management, as it wouldn’t be responsible to enable all Airflow users to have edit access to all of our 600 DAGs. First off, we integrate with LDAP (Lightweight directory access protocol) to add the users to the groups created for their respective teams. Then, any time we update the DAGBag, we refresh the edit permissions for the DAGs. This leads to a permission setup where all colleagues have read-access to all DAGs, while the edit permissions for DAGs are reserved exclusively to the (co-)owning teams of each DAG.
Updating of the cluster
To ensure we have the latest security fixes, and of course the latest features, we try to regularly update Airflow. Because we built several additions upon Airflow, which we shared on the Airflow Summits in the past[1][2], this is not a straight-forward process. We first check the changelogs for breaking changes, then we proceed to do local testing and change our code to be backwards & forwards compatible. Finally, we do thorough tests on our sandbox cluster after which we deploy it for our tenants.
Challenge 2 — Preparing for the worst: Handling machine failures
The more machines you have, the more likely it is to have hardware issues. We encountered this multiple times. Airflow has procedures in place to handle these scenarios well, one such example is that the scheduler automatically picks up queued tasks from other schedulers that died. However, for databases this is less trivial. As mentioned before, we have a highly-available (on-premise) PostgreSQL setup. For this we use Patroni. During failure scenarios in the past, the primary PostgreSQL server went down, causing one of the stand-by PostgreSQL servers to take charge. The so-called ‘fail-over’ scenario happened. Although the fail-over made sure that the PostgreSQL service remained accessible, we noticed that some states of Airflow tasks would still be marked as running, even though they just finished before the fail-over. This caused us to believe we were missing data updates related to the fail-over.
Synchronous commits
The image below illustrates what an update from Airflow to a PostgreSQL cluster with two active stand-by’s would look like. Number 1 indicates any update operation from Airflow. For asynchronous commits, once the update has been written by the primary, Airflow is directly notified that the update succeeded. After that, number 3 and 4 indicate that it will be replicated to the stand-by’s and 5 and 6 indicate the confirmation of replication. For synchronous commits, this confirmation of replication has to happen before the PostgreSQL ledger confirms to Airflow that the update has been successfully written.
If the primary PostgreSQL instance goes down right after an update, operations 3 up till 6 could not be executed for asynchronous commits. This is not uncommon as in some cases there might be considerable replication lag. Even though the primary confirmed the write of the data and Airflow thus got the confirmation it was successfully written, when one of the stand-by’s is automatically promoted to become the new primary, the update will no longer be present as that was never replicated to this node. Synchronous commits protect against this as the confirmation will only be given once the replicas have written the data.
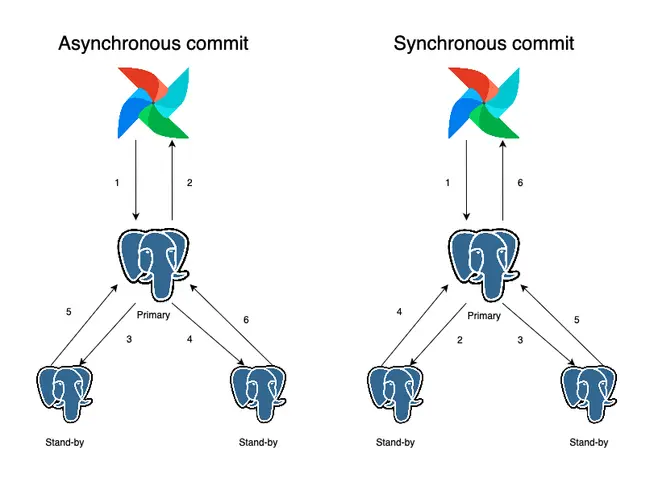
We choose to switch to synchronous commits, so that our PostgreSQL cluster guarantees to have written each change to all PostgreSQL nodes, before the transaction’s success is sent to the application. This means that even when the primary PostgreSQL server dies, we have two up-to-date stand-by PostgreSQL instances, containing the exact same data, ready to take over. With this setup, we feel more confident as we will be even less impacted by hardware failovers.
The drawback of this approach is that it will noticeably slow down each write to the database, and thereby Airflow processes that use lots of writes will take a performance hit. In our case, we noticed the scheduler performance degraded by around 10%. Although that might sound large, at our stage it would be easily compensated by adding another scheduler.
Machine performance
With this setup you can not just pick any server as your PostgreSQL stand-by node. The stand-by nodes need to be at least as powerful and have the same hardware profile as the primary. The disks need to have the same latency to prevent extra hardware latency, and the CPU needs to be as powerful as the primary, in the case of fail overs. Furthermore, they should also be closely located to each other to reduce network latency. This means in the same data center but preferably not in the same rack, in case the entire rack is affected. Ideally, you would also not run any other applications on these machines. We had cases in which other applications on one of the stand-by machines were taking up to 100% of the CPU while hardly leaving any CPU cycles for PostgreSQL. Due to the synchronous commit setting, this slowed down all write operations, making our Airflow setup excruciatingly slow. We were only able to schedule a couple tasks per minute, when we expected to be able to schedule over a thousand tasks in that same period.
Challenge 3 — Handling task priority
As the number of our DAGs grew with time, so did the dependencies between DAGs. To handle those dependencies, we have a modified version of the ExternalTask sensor that handles those dependencies. By default, the sensor pokes the database every 5 minutes to verify whether the task(s) in the other DAG has already successfully executed. We currently have thousands of these sensors running on a daily schedule. Most of them are scheduled at the start of each new day, so the pressure on our system coming from all these sensors is immense. Especially on our test clusters, the sensors were taking up a very large portion of the resources, as these clusters are considerably less powerful.
Priority weights
We looked into ways to improve this and one of the items that we looked into was the priority weight of the tasks. The priority weight decides whether it should prioritize based on the number of downstream tasks, number of upstream tasks or an absolute value the user has to specify. By default, this is set to the number of downstream tasks. In our setup, this means it would favor running sensors over any of our ETL workloads.
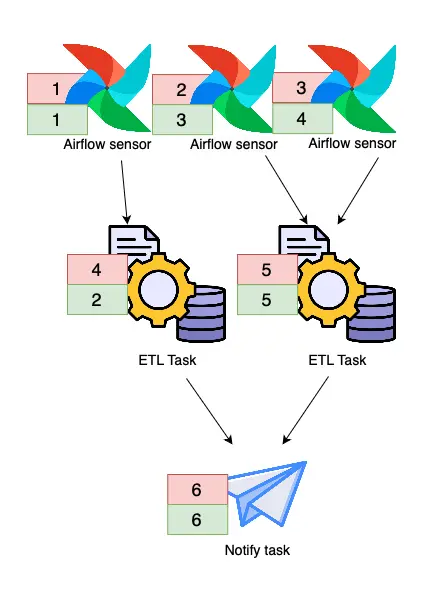
A simple DAG is shown in the image below with the order of execution mentioned in the colored squares. With the default settings, the order of execution would often be as depicted in red. It would try to make sure all sensors succeeded before continuing with any ETL task. This led to a waterfall of delays, as the ETLs would be suppressed by the sensors, causing the sensors to wait even longer on all the ETLs to finish, causing more suppression of running the ETLs.
To prevent this, we changed the priority mechanism from downstream to upstream as the new default inside the airflow configuration file. In case the first sensor would succeed, it would proceed to running the ETL Task next, instead of making sure all the other sensors succeeded as well. This means it prioritizes our ETL tasks, which decreased the average number of pokes executed by sensors and hence resulted in a more efficient setup when our cluster is under heavy load.
Challenge 4 — Maximizing user productivity
At Adyen, we have hundreds of DAGs with thousands of tasks running on a daily or even hourly basis. You might be asking yourself, who is maintaining all of these DAGs?
The Adyen way of working is to empower the engineers, which means that we provide a lot of freedom when productionizing ETLs and machine learning models. This freedom brings domain teams the autonomy to create and maintain their own DAGs according to their data needs. The flipside of this autonomy is the responsibility to assure the platform is stable and performant. Our Adyen platform teams facilitate this by enforcing best practices when it comes to automation and testing.
To reduce the amount of bugs in our DAGs, our data developers have a few must-do’s before merging any changes:
Run pre-merge tests that are not part of our CI/CD pipelines
Dry-run local DAGs
Monitor DAGs in beta and test environments
Add data quality checks
Run pre-merge tests
When it comes to the pre-merge tests, we have a number of things that are relevant such as the DAG sensor and operator dependencies, as well as the task itself — are the resources sufficient or do we need to increase them for the task to succeed?
To cover these and more potential issues, we run a number of tests including the following:
DAG is AdyenDag (we have our own DAG class to overwrite values when necessary)
DAG IDs are unique and match their filename
DAG sensors are sensing existing tasks
DAG tasks are not using PII (Personal Identifiable Information) data unless whitelisted
DAG ETL tasks align with the pre-defined table schemas
DAG owners are correctly specified (each domain data team fully owns their DAGs and thus governance is very important to us)
Dry-running DAGs
After running these unit tests, we proceed with dry-running our DAG by opening the Airflow webserver on our local machine and starting a dagrun of the DAG that we altered. Here we often catch DAG import errors due to misconfigured sensor and task dependencies. In order to run the DAG locally, we start our airflow services through an in-house built CLI tool. Running our own Airflow service command means the PostgreSQL DB, Airflow scheduler, Airflow DAG processor, Airflow Celery Worker and Airflow Webserver are all spun up, ready to run our DAGs locally.
Monitoring DAGs in test environments
Any changes to our DAGs are first released in our beta and test environments before hitting production. We enable the vast majority of our DAGs in both beta and test environments, which means the tasks are monitored for a few days and any bugs that were not caught in our pre-merge testing processes can be fixed at this point before the changes are released in our live production environment.
Data quality checks
To maintain high data quality across all pipelines, our engineers created a performant and user-friendly in-house data validation framework, which allows us to check various data requirements such as columns having only unique values, or columns containing a certain set of values. We also check for proportionate data discrepancies over a rolling time window to make sure we don’t write more or less data than expected. Our data reporting team is currently working on preparing this data validation framework to be open sourced to the community.
Challenge and future ideas
The main challenge that we face with this setup at the moment is the time it takes to run the Airflow unit tests. Our own custom DAG tests are quite in-depth as outlined above and take around 20–30 minutes to run per DAG. The biggest chunk of this time is consumed by the schema tests, which require a spark session to create empty mock tables. This is also the test that catches the most errors, so it is crucial for us to keep it in the test suite.
Since the thorough DAG testing process is quite time-consuming for us, we are looking into options to speed up this process. We recently came across the in-built dag.test() functionality, which could help us catch errors quicker, since it doesn’t require the Airflow service to run and works for custom operators.
TLDR;
In this blogpost, we shared a few challenges that we encountered while aiming to achieve reliability at scale at Adyen with Airflow.
First, we run each Airflow component on at least three servers and regularly update our Airflow instance. To ensure data is never lost, we changed our database setup to use synchronous commits. To smoothen the process, we changed our DAGs to all favor ETL tasks over sensors. Finally, to keep our Airflow users productive, we created a range of comprehensive testing suites that can be triggered either locally or automatically as part of our CI/CD pipelines. However, we are still working on improving this test setup to make it more efficient and less time-consuming for our data experts to alter their DAGs.