Article
Data Engineering at Adyen: Engineered for High Quality Data
by Natasha Shroff & Jari Meevis, Data Engineers, Adyen

At Adyen, data is ubiquitous. Our production systems deal with thousands upon thousands of events per second, our analytics systems are scaled to store and process petabytes of data and our machine learning models need to combine those capabilities. In a highly competitive industry, it is important that we can rely on the correctness, timeliness and usefulness of our data.
This is where data engineers come in: data engineers at Adyen are responsible for creating high-quality, scalable, reusable and insightful datasets out of large volumes of raw data. In this blog, we will take a look at what that actually means, how we go about it, and how we fit within the wider organization.
A little background on our data roles
Over the last few years, we’ve seen an explosion in data related roles. As companies became aware of the impact data can have, they have shifted resources into building their data teams. Of course, as these teams grew, it became more important to clarify the different roles.
We highlighted the way we distinguish data roles in our blog post aboutdefining data roles when scaling up data culture.If you just want a quick overview of the main roles under our data umbrella, have a look at the image below.

An overview of the data roles under our umbrella
At Adyen, we strive to give autonomy to our engineers. This has two advantages for our engineers: they can quickly make decisions within their area of expertise and can enjoy a safe environment for creativity and experimentation. Therefore, our data engineers are encouraged to choose projects based on skill, experience and interest within their team and even expand their work across teams.
At other companies, the data engineering role is sometimes calledanalytics engineer. However, because the job scope and focus of our data engineers is broad and can vary per team, we thinkdata engineeris more suitable.
But what does it mean to be a data engineer at Adyen?
Data engineers are developers first
Unsurprisingly, data engineers spend most of their time… on engineering problems. We use Python andPySpark to define how our data needs to be processed. We validate our input and output data by using both automated testing, data quality and validation tooling.
We orchestrate pipelines usingAirflow. We analyze and explore data usingJupyterHubnotebooks, tied to ourApache Hadoopfilesystem andHivemetastore.
In a regular week, we use about 70% of our time for code development, and 5-10% to review our peers' code. The remainder is split between other responsibilities, such as working with stakeholders, exploring foreign key constraints, launching new initiatives, squashing bugs, sharing knowledge and learning from our colleagues across various roles and teams, or just connecting with fellow Adyeners over a cup of our barista coffee!
What you might also find interesting is that we do not write ‘raw’ SQL in our day to day job. All data transformations are performed with PySpark to keep things scalable.
Of course, a good foundation of SQL is still crucial for our day to day work since PySpark allows us to apply SQL-like analysis using a Python interface.
Moreover, we are also not really responsible for the functioning of the platform: this means we do not have to ensure there are enough airflow workers, or that we need to ingest raw data from event streams. This is done by our data platform engineers, and we trust them to do a good job 👍
Still not clear how data engineers fit within our data landscape? Have a look at the flowchart below.
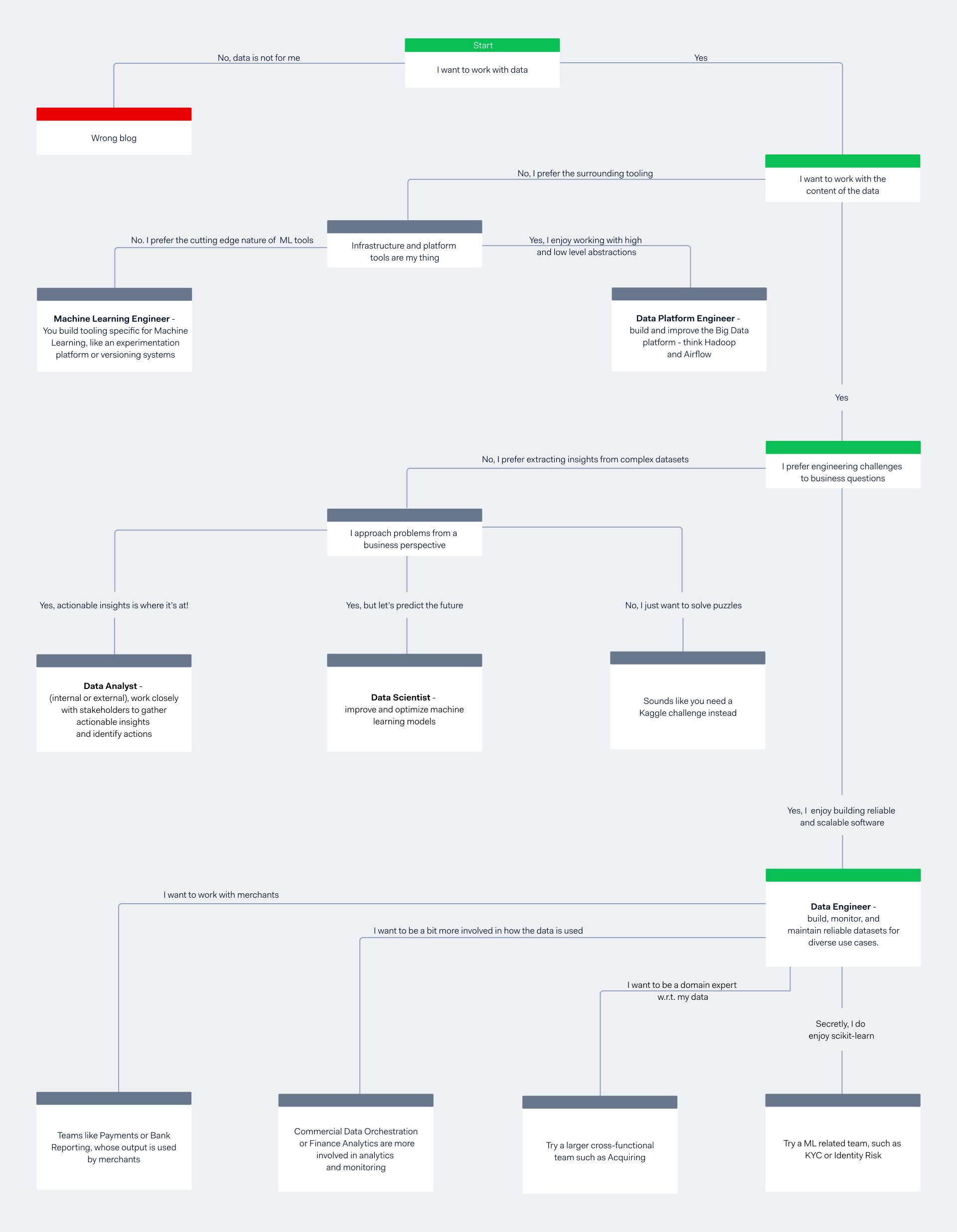
The differences between data roles - now in flowchart format!
How we collaborate across the company
Data engineers are the connection between the raw data and resulting products and insights.
Our motto is: engineered for high quality data. That means that we are responsible for ensuring our downstream users can rely on the datasets we build for them.
Our data has to be validated, tested, and monitored from the time we ingest, to the point at which our analysts are creating insights from the data.
As you can imagine, a close collaboration with all stakeholders is key to achieving reliable datasets that can confidently be used to make meaningful business decisions. Therefore, our data teams are generally oriented by domains and are cross-functional.
A team might consist of data analysts, data engineers and data scientists, headed by a technical team lead and product manager, who all work together to develop a product.
In terms of time spent working together, the closest collaboration happens within the team, followed by other stakeholders, suppliers and domain experts of the data in related teams.
While engineers always have the possibility to work directly with stakeholders, the product vision is generally set by the product manager. Data engineers are encouraged to understand this vision well enough to make their own decisions where possible.
Within the team, we could collaborate on the following themes:
- Optimizing existing queries or data jobs with other data platform engineers and data scientists.
- Identifying requirements for new data sources with data scientists and analysts.
- Drafting and developing new summary tables based on stakeholder requirements.
- Proposing and refining technical solutions with the team lead and other data engineers.
- Implementing and sharing best practices when it comes to data orchestration, validation, testing and governance.
- Monitoring production data and fixing bugs .
- Feature development in mob programming sessions with data scientists.
- Learning and researching state of the art data practices together with the whole team.

We extend our collaboration beyond our team in the following cases:
- Working with stakeholders and the product manager to understand the vision, to allow engineers to work more autonomously.
- Going over code requirements and thinking about data implementations with Backend Developers.
- Working on smaller tooling features together with data platform engineers or other tooling teams, such as extensions to Airflow or a bespoke data validation framework.
- Abstracting complex but commonly used logic away into a shared Data API with data engineers in other teams.
As you can see from the examples above, we collaborate with a wide variety of roles. Our position between suppliers of the raw data and stakeholders of the transformed data is unique and requires a good understanding of both worlds. If you would like to read more about how we create industry-leading services together, have a look atthe Adyen Formula.
Conclusion
In this blogpost, we highlighted important aspects of data engineering at Adyen. We gave you insights on how our role fits into the data landscape, what our job consists of and how we collaborate together. We hope that you have a much clearer understanding of our work after reading this post.
If you are interested in applying to the Data Engineering role, have a look atour careers pageto see all open roles!