Article
Driving Operational Efficiency at Adyen through Large Language Models (LLMs)
By Rafael Hernández (Operations AI Lead) and Andreu Mora (SVP/Global Head of Engineering Data), Adyen

Everyone's been talking about OpenAI’s ChatGPT, and it's easy to see why. It has sparked the curiosity of everyone in the world, including Adyen teams, leading to numerous requests and initiatives inside the company. Some frequently discussed initiatives revolve around interacting with a knowledge base of documents and improving our operations efficiency. Immediate attention was given to understanding the licensing options and ensuring the control and safe usage of the technology.
At Adyen, it took us a moment to comprehend how we could add value with such impressive technology. It is, in the end, quite common and understandable that our urge to fidget with the new technology prompts us, engineers, to find problems to solutions - instead of solutions to problems. This is in our nature, to learn and grasp technology. On the other hand, OpenAI, and others, have made it extremely convenient to leverage such power through APIs, which makes it possible to get results in a shocking short time at the expense of learning the details.
As engineers at Adyen, we don’t take emerging technology at face value and we prefer to peek under the hood, understand the dynamics, details, limitations and risks. At the same time we also assessed where we would add the most value in the organization using NLP (or an LLM) and we landed on improving our operational efficiency for our support teams.
This is why, behind the buzz, we established a dedicated team of Data Scientists and ML engineers at Adyen’s Tech Hub in Madrid. This team is actively leveraging the possibilities offered by Large Language Models (LLMs) and Natural Language Processing (NLP) applications to streamline and improve operations.
Adyen is experiencing rapid growth and, as a technology company, we are looking for ways to scale efficiently. Therefore, at this moment, any initiative related to operational efficiency and automation is highly relevant.
Meeting Expectations in Customer Service
Consider a common scenario, for example facing a stomach ache or a similar small illness with no apparent cause. In such situations, we often rely on healthcare professionals for diagnosis and treatment. However, sometimes the diagnosis is not straightforward and it may take weeks of pain for the patient, multiple visits and redirects to different professionals before finally meeting the correct specialist who can accurately identify the root cause of the problem.
This story illustrates an important principle; whether in healthcare or any service industry, the goal is to solve the client's problem as quickly and efficiently as possible. This requires promptly identifying the right specialist and the tools to tackle the issue. This aligns with the mission of the Operations AI team at Adyen: We aim to use Natural Language Processing to quickly route support cases to the right specialist, accelerating resolution times. Similarly, we use generative AI and LLMs to provide answer suggestions to empower our operations teams, much like having the correct diagnosis and treatment readily available bolsters efficiency in solving problems.
The Pragmatism of Simplicity: Not Every NLP Problem Needs a Hammer (or a LLM)
As we embark on our journey to enhance Adyen's operational efficiency through NLP, it's important to recognize that not every NLP problem may require the latest state-of-the-art LLM. While the allure of cutting-edge technology is undeniable, sometimes a more pragmatic approach can be just as effective.
It might be fair to remark how difficult it is to come to this decision, given the current macro environment. Indeed, every other engineer would have understandably used this problem as a frame for an LLM application. However, our engineering practice has taught us that Occam's razor is our friend and if there is a simple -yet impopular - way of solving a problem then that should be our choice. Operational complexity and technical debt are monsters that are further in the horizon, yet, very real.
For instance, support case routing can be easily framed as a multiclass classification problem using historical records of manually classified cases for training a machine learning model. In this case, a well-established and simpler pipeline that combines Term Frequency-Inverse Document Frequency (TF-IDF) with a Stochastic Gradient Descent (SGD) classifier on top can do the job effectively.
The steps of this approach involve:
Converting text data into numerical vectors using TF-IDF, which analyzes each term's value in a document relative to a collection of documents.
Applying a classification algorithm on the TF-IDF vectors to predict queues for each support case.
This example uncovers how a more pragmatic approach, much in line with Occam's razor, has several advantages:
Interpretability: Understanding why a particular classification decision was made is more transparent with this approach. It can be crucial for auditing and fine-tuning the model's performance.
Efficiency: For many text classification problems, including ticket routing, this approach can yield high accuracy and efficiency.
Maintainability: Implementing this pipeline might require fewer computational and operational resources compared to training a LLM for the task.
While this approach may not have the flashy reputation of the latest LLMs, it scores close to 80% accuracy in assigning tickets to the right queue, which is close to the costly human level performance. It also outperforms other commercial solutions we explored. If we decide to leave the most complicated cases to manual triage, using a threshold based on the confidence of the model, the performance can be even higher.
In our quest to optimize operations at Adyen, we must remember that the simplest tools can often provide the most practical and efficient solutions. Whether you choose to wield a sledgehammer or a precision instrument depends on the task at hand, and for some NLP challenges, simplicity and pragmatism can be your most effective allies.
Leveraging QA Suggestions through Retrieval Augmented Generation (RAG)
One of the top applications of LLMs comes in the form of slightly different names depending on who you ask: contextual question answering, document based Q&A, retrieval Q&A, Chat with your data, etc. Their aim is to assist support agents by delivering AI-enhanced, prefilled responses derived from a repository of documents and records, which can be tailored as needed.
The primary goal of this project is to decrease the initial response time for new tickets by providing automatic, accurate answer suggestions - reducing significant workforce hours.
This is achieved through Retrieval Augmented Generation (RAG). RAG leverages an existing document database to generate contextual suggestions, streamlining the process and linking responses in the available knowledge base.
Creating a productive RAG application, however, requires more than an LLM. Some crucial building blocks include:
A collection of relevant, public or private documents that can augment the context to solve the query in a support request.
Some transformations for generating chunks with the meaningful information to be retrieved and for calculating the embedding.
An embedding model to vectorize these chunks and the ticket query during inference for semantic similarity search.
A vector database to store and retrieve the document/chunk vector representations, allowing relevant document identification based on similarity metrics with the ticket query.
A polished prompt notifying the LLM of the relevant documents in context (there is a complete new area of expertise known as prompt engineering).
Finally, a LLM to generate an answer to the ticket query using the retrieved context.
It's worth noting that Langchain, regardless of the type of model employed or the database technology for the vector store, acts as the “glue” to connect all these components and to build end-to-end applications. It gives you the flexibility, for example, to decouple the chosen LLM from the rest of the application components, thus greatly simplifying the development process.
Proprietary models vs Open-source
It is important to highlight that Adyen adheres to certain core principles. For example, we have a strong preference for building in-house or using Open-source software before using a vendor, especially if that is a technical competence that we want to maintain expertise in the team. With respect to LLMs, as of the time this post was written, GPT-4 stands out for its exceptional performance. However, at Adyen, we are keen on exploring the potential of Open-source alternatives like Falcon, Llama-2 or Mistral, which are easily available in public repos such as HuggingFace’s model hub.
Current trends indicate open-source LLMs are closing the performance gap with proprietary ones such as GPT-4. We often prefer open-source for several reasons:
Cost: Open-source models have no licensing or usage fees, and while there's an investment in the required hardware, it can be offset in the long term.
Data privacy and security: Hosting Open-source models in our infrastructure means sensitive data stays within our network.
Customization and flexibility: Open-source models can be customized and fine-tuned for better performance on specific data.
Community support: Open-source communities provide support, assistance, and a rich avenue for improvements.
Learning: It promotes understanding of machine learning and NLP technologies.
Control and long-term viability: Open-source models reduce dependency on external vendors, ensuring project viability and avoiding lock-in effect.
Explosive innovation: since the introduction of the initial Llama model, the Open-source community has released a number of improvements at an impressive speed and pace. These improvements have also been adopted by private players.
While Open-source LLMs present numerous benefits outlined earlier, self-hosting presents its own challenges, even with a robust infrastructure of GPU clusters. However, our experiments with Open-source LLMs such as Falcon 40b, Llama-2 40b and Mistral 7b have yielded promising results for the tasks we've targeted.
Another option to address privacy and security concerns with proprietary models is the recent OpenAI's enterprise. This choice, being separate from the standard OpenAI API, offers a mitigation strategy against potential risks stemming from relaying support case information to a third party.
Building a RAG pipeline with Open-source and self-hosted LLMs
Retrieval Augmented Generation (RAG) is gaining traction across industries for improving customer support, knowledge management, and more. There are plenty of resources documenting how to build RAG applications, but creating such a system entirely self-hosted and using Open-source software can be challenging.
The following diagram provides an overview of the components involved and what kind of technical decisions we have to make. In some cases, these decisions are not set in stone, but frequently reviewed, in terms of the advantages and disadvantages of each of the possible options. The fact that this technology is advancing rapidly is an additional argument in favor of using a framework like LangChain that allows for easy interchangeability and decoupling of components without causing a major refactoring of the final application code.
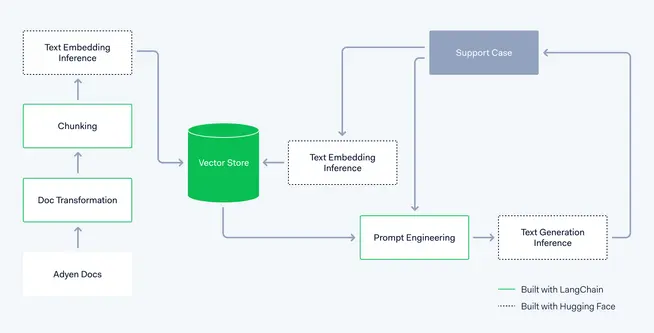
Document loaders
Loading documents from Adyen's websites and private sources is a multi-step process, involving web scraping, document retrieval and secure access management. Along the process it might be necessary to clean text to remove any unwanted elements, such as HTML tags, scripts, or other non-textual data.
LangChain also incorporates off-the-shelf components for web scraping and document management. This is usually the first step of the flow in any RAG application.
Chunking strategy
Given the diverse nature and structure of real-world documents, it might be very useful to leverage different document transformations, rather than applying a simplistic character/word-split approach.
The chunking strategy ensures that the massive collection of documents you have is broken down into meaningful, coherent, and efficiently retrievable units. There are some elements that need to be considered in the chunking strategy:
Granularity: Optimal chunk size is critical. Oversized chunks can yield excess information, causing inefficiencies, while undersized ones may lack context.
Overlap: Slight overlaps between chunks can capture full context and prevent loss of relevant information.
Metadata Attachment: Linking metadata to each chunk, like its source (e.g., help.adyen.com) or category, helps with later retrieval prioritization or filtering.
Text Embeddings Inference (TEI)
For a while SentenceTransformers has been the only real alternative to the Open AI API, where text-embedding-ada-002 sits as the most widely used model. SentenceTransformers is more suitable for rapid prototyping, but has room for improvement regarding latencies and throughput, especially when thinking about scalable and reliable solutions in production. HuggingFace’s Text Embeddings Inference (TEI) is a toolkit for deploying and serving Open-source text embeddings models. It supports all top 10 models of the Massive Text Embedding Benchmark (MTEB) Leaderboard.
Previously, Open-source embedding models were restricted to 512 context windows, falling behind OpenAI that accommodates up to 8191 tokens. Yet Jina AI, a Beling-based AI company, has launched jina-embeddings-v2, its second-generation text embedding model, and the only open-source model that supports an 8192 token context length. It matches OpenAI capabilities in terms of both capabilities and performance on the MTEB Leaderboard.
TEI, at the moment of writing this post, is the fastest solution for embedding extraction available. It offers seamless serverless solutions and quick embedding extraction within a ready-to-deploy Docker image.
Vector Store
A vector store is a specialized database that is optimized for storing documents and their embeddings, and then fetching the most relevant documents for a particular query.
Initially, we assessed Redis and Cassandra, technologies already available at Adyen, mature and well-supported by extensive communities and documentation. These options, capable of handling various data types including vector storage, might reduce the need for maintaining multiple systems.
While both Cassandra and Redis are robust databases, they don't offer the same level of optimization for vector data storage and querying as specific solutions like LanceDB or ChromaDB, which we are also evaluating.
Prompt Engineering
Prompt engineering involves strategically formulating text inputs and instructions for language models to generate desired results. This process, essential in shaping the model's behavior, demands precision and creativity.
For example, when prototyping for RAG applications, we found that introducing a context compression step can significantly enhance the performance, particularly when managing limited tokens. This component, facilitated by LangChain's contextual compressor, refines the context before feeding it into the generative part of the LLM.
Prompt engineering often involves rounds of trial-and-error, frequently drawing on tested templates developed by industry experts. These provide a robust foundation for desired outcomes and optimization of interactions with LLM. Within the LangChain framework, one of main modules significantly facilitates prompt engineering by establishing templates that are versatile across various language models.
Text Generation Inference (TGI)
Text-generation-inference is a solution developed by Hugging Face for deploying and serving large language models (LLMs), enabling high-performance text generation for various popular Open-source LLMs such as Llama, Falcon, StarCoder, Bloom, GPT-Neox, and T5. It implements several optimizations and features like batching, caching, beam search, top-k filtering, and gradient checkpointing. Additionally, it offers a unified interface across different models and handles memory management, making it easy to switch between models, accelerate, and scale up.
The container is production-ready and is a reliable solution that powers Hugging Chat, the Inference API and Inference Endpoint. LangChain already incorporates a class to use TGI in any chain in a very straightforward way.
from langchain.llms import HuggingFaceTextGenInference
llm = HuggingFaceTextGenInference(
inference_server_url="<SERVER_URL>",
max_new_tokens=512,
top_k=10,
top_p=0.95,
typical_p=0.95,
temperature=0.01,
repetition_penalty=1.03,
)
llm("What do you think about Adyen?")
Note: In order to use TGI in a self-hosted manner you only need to download the model weights and choose among Falcon, Llama2, Mistral or any other Open-source LLM, preferably in Safetensor format, and attach those weights to the container that runs TGI.
Debugging, monitoring and evaluating RAG application
Once you have all the previous components in place, it might be easy to start prototyping some applications. Transitioning LLM applications into production is a complex journey. This demands considerable fine-tuning and customizing of several elements, such as prompts and chains.
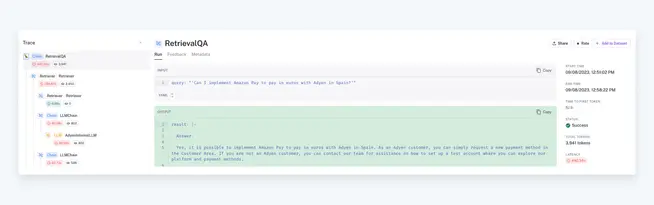
To navigate this phase, we have been using LangSmith. This platform integrated seamlessly with LangChain, allowing us to debug, test, evaluate, and monitor complete LLM chains effectively. It enables us to:
Debug new chains, agents or tools on the fly
Evaluate the relational use of chains, LLMs, retrievers, and more
Assess different prompts and LLMs for individual components
Run a specific chain repeatedly to verify consistent quality
Capture usage traces and generate insights with LLMs
LangSmith offers quick debugging of nested prompts, monitors latencies, tracks token consumption at each stage, and evaluates responses against user-configurable metrics.
We employed Grafana and Prometheus for fundamental monitoring and logging. These tools help track key metrics and system performance.
For the assessment of RAG applications, we have explored different frameworks, eventually choosing RAGASt offers a comprehensive mix of metrics such as faithfulness, context relevance and precision.
It utilizes either expert answers as a source of truth, or responses from advanced models like GPT-4.
What’s next
Looking ahead, we have ambitious plans: fine-tune our own models, further enhance their performance and maximize the abilities of Retrieval Augmented Generation.
Fine-tuning involves adapting these Open-source LLMs to the specific challenges and terminology that are unique to Adyen. This process will require the creation of a dataset of instructions and examples tailored to our operational needs. Through fine-tuning, we aim to ensure that our models understand and respond to Adyen-specific queries and cases.
We're thrilled to keep moving forward and unlock the full potential of language models. We want to be more than witnesses of this technology revolution. We are in the unique position to apply machine learning to drive the operational efficiency of a global, high-reliability, high-volume platform. We strive to contribute to the journey of ML and LLMs, sharing what we learn from their usage at scale. It's ingrained in our culture to be subscribed to innovation.