
Article
Combating Marketplace Seller Fraud with Graph Neural Networks: A Journey to Enhanced Security
By Feng Zhao, Tingting Qiao and Erdi Calli, Data Scientists, Platform Risk.
Marketplace seller fraud is an ever-evolving challenge that poses significant risks to merchants' financial security. It consists of a range of malicious activities, for example: identity theft, phishing attacks, credential stuffing, and account takeovers. These fraudulent actions not only result in financial losses but also harm a company's reputation and erode customer trust.
While business rule-based models and traditional machine learning (ML) algorithms have been effective to some extent, they struggle to keep up with the increasing sophistication of fraudulent activities. To safeguard merchants' funds and ensure a secure marketplace, it is crucial to continuously improve our fraud detection methods.
In this post, we take you behind the scenes to explore how Adyen leverages the Graph Neural Networks (GNNs) to protect our customers' interests.
The Battle Against Seller Fraud
At Adyen, the Score team is the team dedicated to detecting seller frauds on marketplaces and platforms. Over the years, we have deployed a combination of business rule-based models and traditional ML algorithms. These algorithms detect frauds every day among millions of sellers, in a scalable way, to secure both our merchants and the Adyen platform, and they have demonstrated satisfactory results. However, these algorithms look at each seller’s account behavior in isolation. We also believe that by using the lens of graphs, we can uncover more sophisticated patterns by incorporating the interconnections and relationships between sellers. This approach allows us to gain deeper insights into the ecosystem and better understand how various sellers may be collaborating or influencing each other, ultimately enabling us to enhance our fraud detection and prevention strategies.
Enter Graph Neural Network Models
Graph Neural Networks (GNNs) offer a promising solution to elevate fraud detection capabilities. It is a class of neural networks specifically designed to work with graph-structured data. GNNs can capture complex patterns and dependencies; allowing us to detect subtle fraudulent activities that rule-based models and traditional ML approaches often miss.
In recent years, GNNs have gained traction for fraud detection problems in industry. To reference a few; Uber proposed an experimental solution to detect cooperative frauds, and Amazon leveraged the AWS platform to productionize GNNs for the fraud detection. Still, it remained a challenge to apply this new idea to seller fraud detection in production at Adyen.
In the next sections, we share about how we were able to address this challenge. We show how we modeled the seller fraud detection problem as a GNN problem and solved the productionization challenge purely using open source solutions at scale.
The Transaction Graph
In terms of the graph structure, we built a seller-identifier graph: where the nodes represent sellers and edges capture the common shopper behaviors between them. The figure below shows an example of this graph:
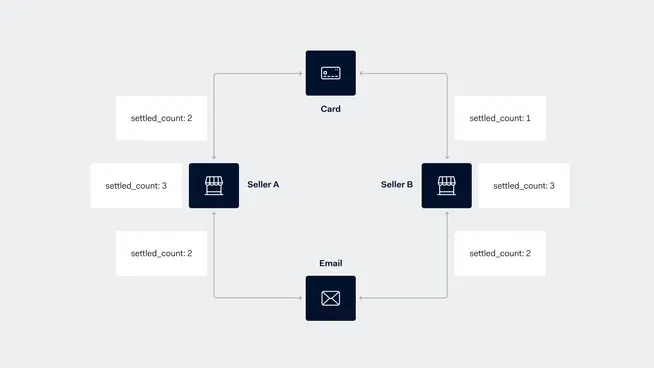
In this graph, we can observe two sellers linked by a few cards or emails associated with their customers. For instance, consider the seller B: this seller received one transaction from the shopper’s bank card ( settled_count: 1 ) and two transactions from the shopper's email address ( settled_count: 2 ). Altogether, seller B has received 3 settled payments ( settled_count:3 ). The edges in the graph indicate if a bank card or an email address was used to buy from a seller. If there is an edge connecting a credit card and a seller, it means that this credit card is used to buy something from this seller.
We have been actively monitoring the states of the sellers on marketplaces, and we keep track of the records; from these, we can tell if a seller is blocked due to fraudulent activities. This means that we can label certain sellers in our machine learning datasets – which is the key step to go forward with supervised learning – and train a model to predict if a seller is performing fraudulent activities or not.
To summarize our approach so far: we framed the seller fraud detection problem as a supervised problem where we aim to classify the states of seller nodes within a transaction graph. Next, let's delve into the details of the approach that we took to train a GNN and apply it in production.
Graph Neural Network Setup: Transductive or Inductive?
When it comes to classifying nodes in graphs using Graph Neural Networks (GNNs), there are two common approaches: transductive and inductive.
In the transductive setting, we work with a single graph where both training and testing data come from the same graph. This means we have access to the entire graph during training, but we lack the labels for the test nodes. On the other hand, in the inductive setting, we deal with separate training and testing graphs. We train our model on one graph and then apply it to a different, unseen graph for testing.
Transductive settings often lead to better performance since they utilize the full graph for training. However, in our specific case, getting fraud labels from the audit trail can take around a month. This delay makes it impractical to use the transductive setting, as we don't have enough labels to train a meaningful model within a reasonable timeframe. Therefore, we opt for the inductive setting, where we split the data based on time, and use the latest available labels based on the run date, as illustrated in the figure below:
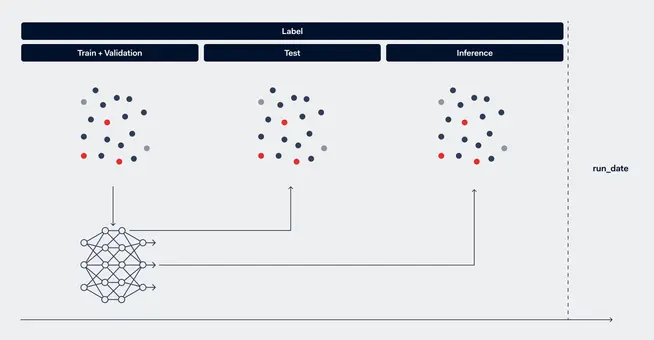
Train + Validation graph: We train a GNN model on this graph and stop the training earlier based on the in-sample validation loss.
Test graph: We evaluate the performance of the trained GNN model on this graph to make sure the model result is stable on the out-of-sample data.
Inference graph: We apply the model to this most recent graph and report fraud sellers who might be involved in fraudulent activities to risk officers.
Putting GNN in production
To flag seller frauds in time and keep the optimal performance, we want to leverage the most recent data and run GNN daily. This presents a significant challenge in the production of GNN. To ensure scalability, we've introduced two key optimizations:
Scalable graph creation using GraphFrames: We use Spark for data analysis and modeling, and we do this at scale for billions of transactions per day. To create the transaction graph, we also leveraged the graph operators in Spark - GraphFrames - which provides a DataFrame-based Graph API to run graph creation in a distributed setup. Also, since the training, test and inference graphs are independent, we further optimized it by running these graph creations in parallel to make full use of the computing resources.
Summarizing graph with bipartite projection: Instead of using the original seller-identifier graph e.g. seller-card, seller-emails, we projected the graph to the seller level and summarized the shopper activities on the edges. This optimization reduced the graph by five times(5x) its original size, and significantly improved the efficiency of our training, testing, and inference processes. As an illustrative example, we've condensed the transaction graph among sellers and shoppers, as previously shown, into the smaller graph below:

In this graph, we can see two connected sellers, each marked with their respective settled_count feature to signify their individual transaction counts. Edge features between them – card_id_settled_count and shopper_email_id_settled_count – represent shared shopper behaviors.
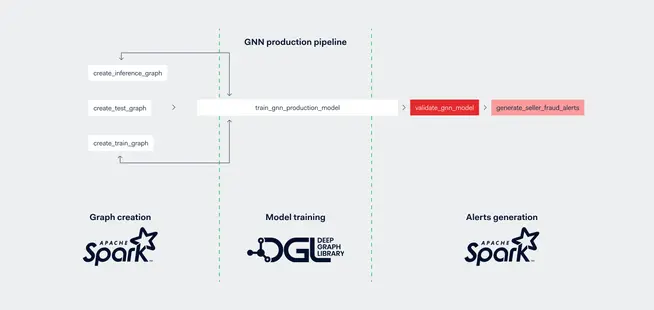
Putting it all together, we implemented the GNN model pipeline using Airflow; our go-to job scheduler to productionize ETL and ML pipeline at Adyen. The pipeline consists of 3 stages (see image below):
First, we create the parallel graphs on Spark.
Secondly, we convert the graphs into DGL format, train a GNN model, and apply it on the test and inference graphs.
Finally, we use Spark to generate fraud alerts with relevant business metrics to make the result explainable for the risk officers.
The whole pipeline runs everyday in production and the end-to-end duration is 2 hours on average.
In Summary
Since the launch of GNN this year, GNN models have consistently outperformed traditional models, showcasing the remarkable effectiveness and power of GNN technology. At Adyen, our commitment to delivering secure financial services drives us to constantly push the boundaries of technological innovation. By leveraging GNNs, we have elevated our seller fraud detection capabilities, making a significant business impact. Join us on this journey of collaboration, celebrate our achievements, and gain insights into the lessons we have learned. Together, we pave the way for a safer and more trustworthy payment ecosystem.