Reports
Design to Duty: How we make architecture decisions at Adyen
Updated June 2022

At Adyen, we have a very pragmatic way of approaching problems. As a result, we use simple tools to achieve great results.
The goal of this blog is to walk you through the challenges we faced in scaling our system, how we tackled those challenges, and how our system looks because of those decisions. In particular, we will pay attention to the choice between home-grown solutions versus open-source software.
In the first installment of the blog, we will discuss these topics as they relate to our edge services, and in the second part, we will do the same for our accounting and reporting layers.
Instead of just explaining how our architecture looks, we thought it would be interesting to explain why our architecture looks that way. At Adyen, we are firm believers in giving developers responsibility. This means responsibility for the design and implementation of a system and also for the security and maintenance of that system. Because the design of our system is done by engineers who are also on duty. These engineers are strong contributors in deciding how to build something, which sometimes leads to counterintuitive results.
Building home-grown solutions or choosing open-source software
New joiners to Adyen are often surprised about some instances in which we built stuff ourselves. Because of this, we thought it would be interesting to discuss some of these choices while going through our architecture. For an extreme example of building it ourselves,see this short video about why we built our own bank. Point 3 inthis blog, about the principles we used to scale our platform, talks more about which technologies we consider for adoption.
When we are confronted with challenges, the proposed solution is often either to introduce a new tool or framework or to write something in-house. From Adyen’s perspective, writing something yourself will give you more flexibility but it will cost more time and probably have fewer features than an open-source alternative.
The usability of an open-source option is likely higher due to better documentation and a larger community, but it might be more complicated, because of additional features that we don’t need and investments in training the people that need to work with it. The security of an open-source option will probably be better because many people vetted it, but the attack surface is also almost always larger.
Our view on vendor solutions
A lot of businesses will also consider vendor solutions, so do we. However, we want to focus on the core flows in our system, and for those, we never choose a proprietary solution because we want to have full control.
We buy instead of build, if the use case is peripheral, it does not have to be real-time, we do not have to embed it, or if it is a good value proposition. An example of this would be some of our KYC background checkers. Of course, avoiding lock-in is an important consideration here.
Adyen at a glance
Adyen is in the business of processing payments. We receive a payment from a merchant; we send that payment to a third party (such as a credit card company) and we return the result. This happens hundreds of times a second, 24/7. We also keep track of all the transactions so we can pass along the money to the merchant once we receive it from the bank. Of course, we also provide reporting to our merchants.
We do this for hundreds of billions of euros every year. In the last couple of years, we have introduced additional products such ascard issuing, a bank, andAdyen for Platforms, which helps platform businesses like ride-sharing or marketplaces. We do all of this on a single platform, in a single repository (monorepo), almost exclusively written in Java.
Our system is divided into several parts that function relatively independently from each other. They are split along business domains. For example, we have one part centered on payment processing and another part centered on the bank. In the data layer, they are tied together. The same design principles are applied for each of the subsystems. So while we mainly cover payment processing in this blog, the architecture is similar across the board.
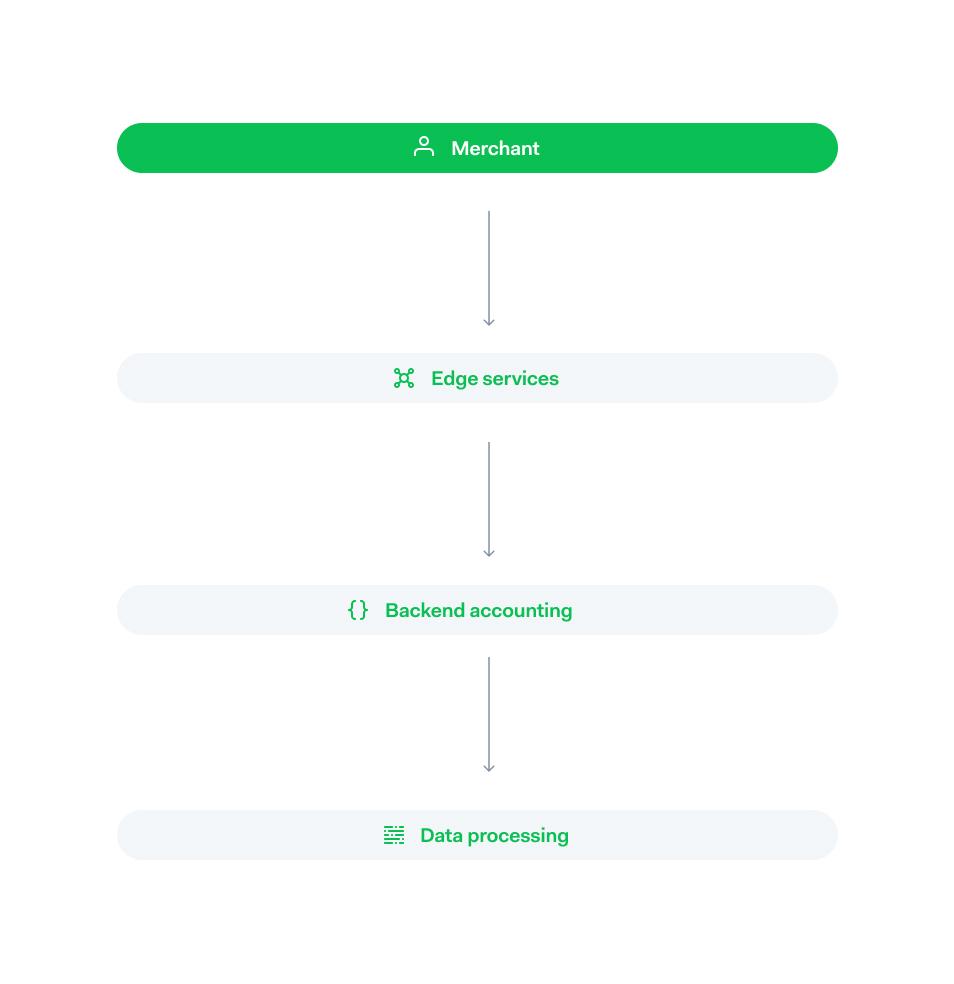
A payment sent in by a merchant will arrive at our edge layer. Here we will do synchronous processing, contact a payment method if needed, and return the result to the merchant again. Availability and low latency are paramount here. In parallel, we sent this payment to our backend systems where we store it in our accounting system. Accuracy and reliability are the key priorities in this part of the system. Finally, the payment ends up in our data processing layer, where the throughput becomes a major concern. We will go through each of these layers, discussing the choices we made that shaped them.
Edge services
Every API call to our systems goes through our edge services first. The payment can come either from apayment terminal, from amobile application, via a direct API call, or from apayment page hosted by us. The Payments Acceptance Layer (PAL) is a crucial service in our edge layer. All payments pass through it.
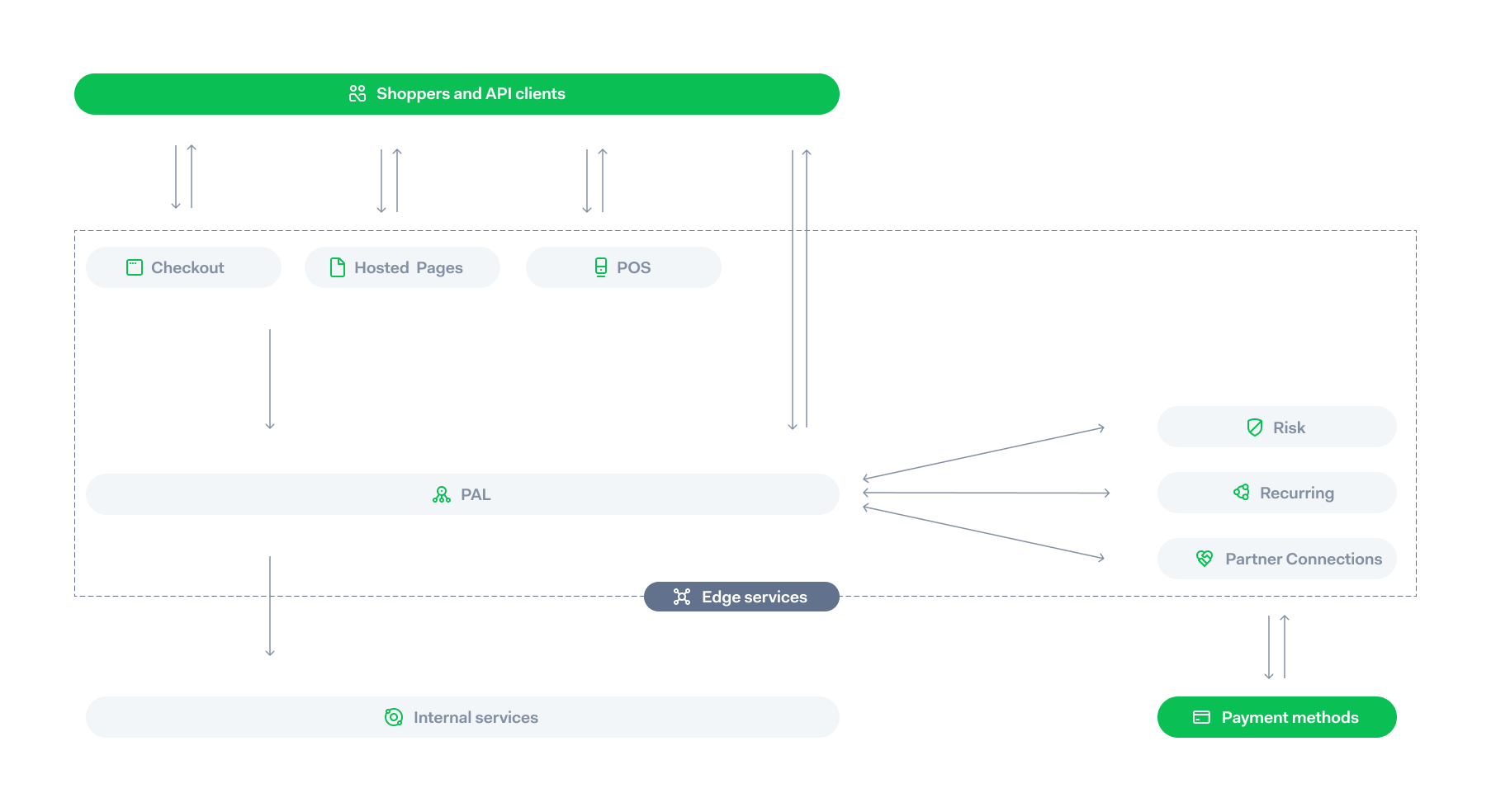
This application will send the payment to our other internal services. These other services can be a risk engine, a service for saving or generating recurring payment tokens, or a service for computing which connection will lead to the highest authorization rate. It will also contact (through an intermediary service) the partner payment method or scheme that processes the payment.
An important design feature is that all payments are abstracted at the PAL so the system can treat them as equal. There are, of course, differences between them. Some will have additional metadata (for Point of Sale transactions this might be the ID of the terminal that processed them). However, they all go through the same system and are stored in the same databases.
The engineers who handled the initial design had already gained experience at a previous payments company. In that company, a payment that would come into the system would keep some state in the edge layer. If a new payment would arrive that modified the original payment, for example a refund, it could immediately be processed as all the required information was already stored in the edge layer.
The problem with this setup is twofold. An application could not go down for maintenance or can crash without affecting our ability to process transactions. The other problem is that a new machine could not immediately process the same volume as an old application. Some transactions needed to go to a specific instance. The state in the application made each instance unique.
Stateless services
Taking a step back, it is possible to see why we did it differently at Adyen. The priority for this part of the system is to be highly available and have low latency. We should always be able to accept payments and process them as fast as possible. Instead of keeping the state in our edge layer, we decided to process modifications asynchronously, which keeps the edge layer stateless.
As a result, any PAL instance can be shut down without impacting our ability to process payments, and a new PAL can immediately be as effective as the other PALs already running. This makes our horizontal scaling linear. In other words, if one PAL can process X payments per second, two PALs can process 2X payments per second. This mechanism has been basically unchanged since the start of the company, testifying to its power.
The fact that the edge services are stateless means that they cannot write directly to centralized databases. This is not only beneficial for scaling the system but also a very nice security feature. All our externally exposed systems are prohibited from writing to central databases, reducing the risk of attackers compromising or stealing valuable data. By ingraining a strong sense of security into developers, we can have security by design, instead of having to retroactively patch holes in the system.
Distributed databases
More recently we faced the challenge of making our payments API idempotent. This means that if a merchant sends us the same exact payment twice, we should only process it once but return the same response in both cases.
As you now know, we do not want to achieve this by restricting payments of some merchants to certain machines, as this would mean the machines are no longer linearly scalable. The information needs to be available locally, so we eventually decided on integratingCockroach, a distributed database, with our PALs.
We could have built something ourselves here (probably on top of PostgreSQL) but this is really not our core business and there were several open-source options that satisfied our criteria. Nevertheless, getting properly acquainted with the DB and optimizing it to the point where we were satisfied with it required a substantial effort. For another example of a decision between open-source and building ourselves, seethis blog on our graph risk engine.
Future Iterations
The next big step for our edge services would be to scale them dynamically. We manage our own infrastructure in several data centers around the world and have bare metal available, but the hardware and software are still tightly coupled.
The reasons we are not deploying to the cloud are part historical, part legal, and part technical. In part, because we now need dynamic scaling, we are moving towards running our system on an internal cloud. A blog on the containerization effort is forthcoming.
Conclusion
I hope this blog shows how we make decisions at Adyen about how to scale and which technologies to use. In all our choices we are highly pragmatic, adhering to the KISS (keep it simple, stupid) principle almost to a fault. This sometimes runs counter to established doctrines in the industry but it shows that you can build a solid company with a small set of trusted technologies.
In the next blog, we will look at the architecture of our accounting and reporting systems. Unlike our edge layer that has remained relatively static, we actually had to redesign the accounting system several times. In that blog, we will also expand more on building home-grown solutions versus choosing open-source software.
Technical careers at Adyen
We are on the lookout for talented engineers and technical people to help us build the infrastructure of global commerce!
Check out developer vacancies