Reports
From 0 — $100 billion: Scaling infrastructure and workflow at Adyen
By Michiel Toneman, SVP, System Architecture, Adyen

Recently, I shared our perspective on building a sustainable stack at Devoxx Belgium (to watch the video, scroll to the bottom of the post). Three of our key insights, put together from scaling a platform from zero to $100 billion in transaction volume and a development team that has expanded from four to over 100, are below.
1. Get everybody working on the main line
Early on we saw that a number of projects that had failed had two things in common:
1. They were developed in isolation, with the code outside of the main line and minimal exposure to other colleagues.
2. When the developer needed to commit their changes, they often did it just before the release — effectively pushing new, unseen code onto the main line that had the potential to cause problems at precisely the wrong time.
Our solution was to make sure our developers are always able to access one another’s changes as early as possible. To ensure this, we implemented an approach where everybody develops on the main line. And when we want to move something to production, we follow this practice:
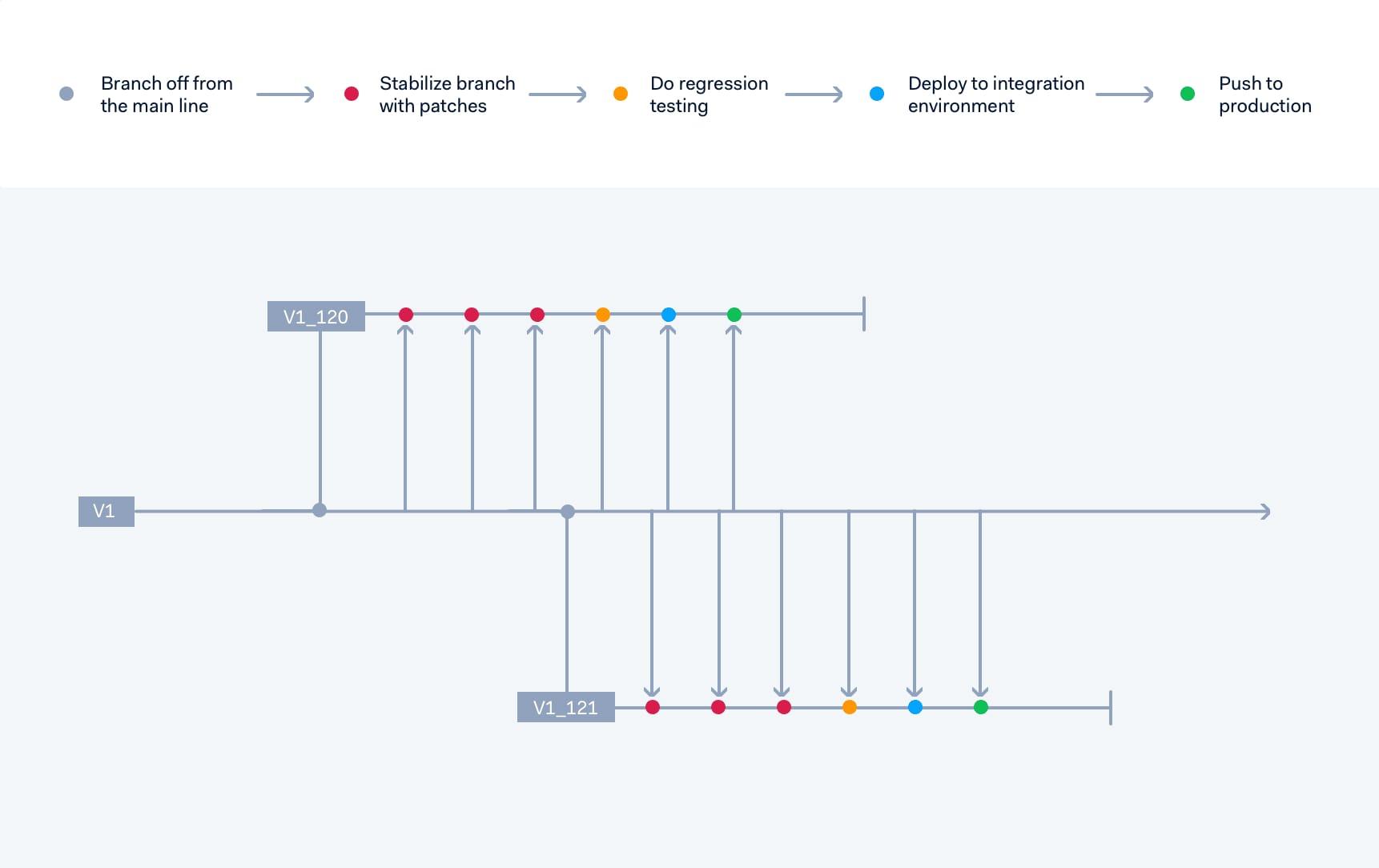
In the integration environment, customers occasionally spot minor issues we missed, and once we are happy we push to production.
This approach is all well and good when everything is moving in a linear manner, but what happens if a fix is needed on production? Or if there is more than one production branch at a time?
If we need to fix something on the production branch, the change is committed to the main line, then later ported to the production branch. To support this approach and ensure its success, we have a four-eyes policy and revision number on the main line, and porting is enforced with a commit hook in the source code repository.
This may cause some short-term inconvenience for the developer. But in the long term, the fact that every fix is on the main line by default ensures that we almost never see recurring bugs.
When we want to do a new release, we create a new branch, which we stabilize, and once it gets pushed to production, the old branch is terminated. Because old changes have already been applied, we don’t have to merge anything back to the main line. And if there are two active branches at any one moment, bug fixes need to be ported to both branches.
2. Commit early and often, but centralize deployment and activation
As outlined above, we strongly believe that everyone benefits from being able to see each other’s code as early and easily as possible. In fact, by having everyone commit on the main line, we incentivize this practice — if you commit first, the person who commits later will have the responsibility to ensure that any potential conflict is resolved.
A consequence of this approach is that code may be committed which will not be used in that production branch. On balance, we prefer the development team to have early exposure to the code commits, than requiring everybody to rush to get project fully complete for the next release, or worse, delaying the project.
Having a large group of developers committing code means you have a large amount of functionality going live every release. This brings an element of risk to each deployment as all of this new functionality is activated at once.
We mitigate this risk by having a centralized and systematic approach to the separation of code deployment and activation. Following thorough testing on dev and integration, we toggle features one-by-one on production, and then canary them to ensure the highest possible chance of a seamless rollout. By maintaining ownership over toggling, we automate the process of alerting our developers about cleaning up old code paths, and activating new features.
3. Be ruthless about your stack
Many development teams are eager to embrace the latest and shiniest software. But when adoption of complex solutions runs unchecked, things have a tendency to break. And if your stack is built on this philosophy, the chances of everything catching fire simultaneously increases dramatically. Don’t be that guy at 3am looking at a mystery error message while unhappy customers crowd your inbox.
Pinterest is a company that has a similar philosophy to Adyen in terms of adding to the stack — so I will borrow and recommend the next concept from them. Pinterest selects their stack by graphing maturity against complexity — where maturity is defined as the level of support, community, and expertise around the product, plotted against its complexity. Like Pinterest, we make an effort to stay in the green zone when we add to our stack.
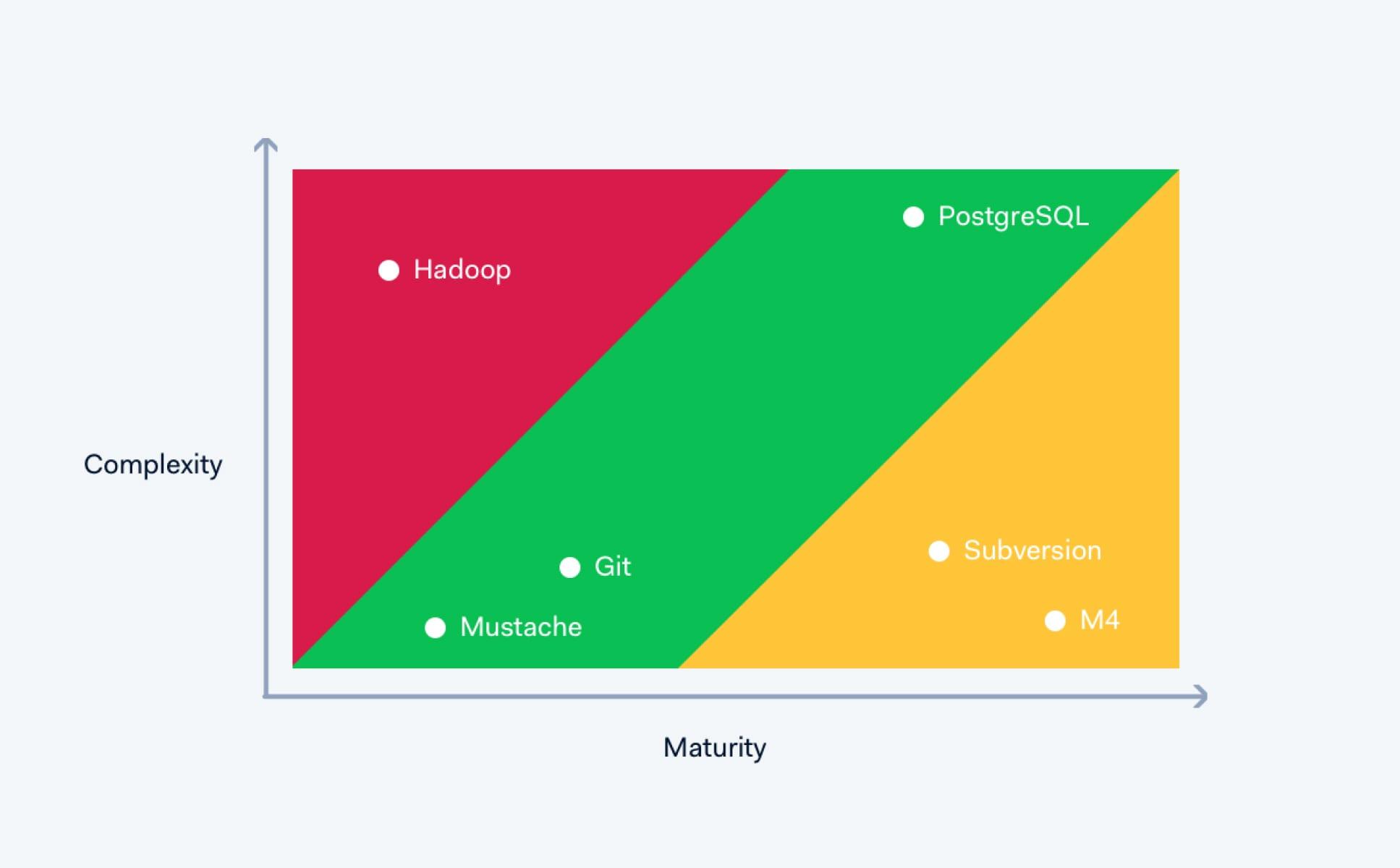
Graphing maturity versus complexity 🐣
Our logic is that if you are deploying something in the red zone — with high complexity and low maturity, you may be setting yourself up for future fires. By contrast, if you play it too safe and rely only on highly mature solutions such as in the yellow zone, you may have sub-optimal solutions.
A key point to consider when identifying where a product sits on the schema is whether or not it matches your exact use case. There are exceptions, but technology developed for highly specific use cases such as Kafka or Cassandra are likely not suitable for an early stage startup. Also, the level of maturity of the developer and support community around a product has implications for the speed of digestion and troubleshooting.
Finally, remember that using something on your dev machine is just the beginning — backing up, updates, failure modes, data migration, and hiring and training, are equally important considerations.
Changing the wheels on a moving car
Overall, I liken doing live deployments with no margin for error to changing the wheels on a moving car. It’s a highly complex process, and the fact that a day’s worth of processing volume on the Adyen platform in 2010 would now be done in five seconds gives you some idea of the scale we’ve built — all the while ensuring uninterrupted service.
Ultimately, every startup has its own requirements and challenges, and therefore needs its own approach. But I hope that our insights might give you some context on how to overcome your own challenges, too.
Technical careers at Adyen
We are on the lookout for talented engineers and technical people to help us build the infrastructure of global commerce!
Check out developer vacancies