Reports
Design to Duty: The Accounting and Reporting Systems at Adyen
By Willem Pino, Tech Lead, Adyen

In this blog, we will have a closer look at how we make decisions around our accounting system and how it evolved as a consequence. We will do the same for our reporting and analysis frameworks.
This is part two of a series. So, if you have not done so already, it might be nice to start with thefirst blog. In that one, we talked about what Adyen does at a high level, how we think about choosing between home-grown and open-source software, and how this shaped our edge services.
The themes that were laid out inpart onewill return and be referenced in this blog. If you didn’t read the first one, it might be that some context is missing.
Accounting system
Once we have processed a payment, the next step is accounting for it. This is needed because after processing transactions, we receive the money from our partners and we need to determine how much to settle to each merchant. Of course, we also need it for reporting.
For every payment that enters the system, we do double-entry bookkeeping. The way we ensure that we do so correctly is quite unique to Adyen. The only way to add new records to the accounting system is by means of templates. A template in this context is a recipe that takes certain amounts and accounts as input and converts them into specific journals that can be inserted into the ledger.
These templates are mathematically verified. To achieve this, we represent the amounts that serve as inputs by logical entities and prove that every combination of amounts will result in a net sum of 0. This verification is fully automated and runs on every change to the templates.
All of this means we can guarantee that if at any time, we sum up all the records in the accounting system, the result will always be 0. Combine this with the aforementioned double-entry bookkeeping, and it means for every euro that ever went through Adyen, we know exactly where it came from and where it went.
We leverage this same system of accounting for our banking platform.
It might be superfluous to mention it, but our accounting framework is also written in-house. Here the choice was evident, it is as core as can be to our business, and nothing in the open-source landscape came close to what we wanted.
Underlying Database
Having all these nice things does come with some cost. Over the lifetime of a payment transaction, about 50 rows have to be inserted into the accounting database. This means that per second, just for the accounting system, the amount of inserts is an order of magnitude higher than the hundreds of transactions we process every second. Some time ago these thousands of inserts a second started to cause issues for our PostgreSQL database.This blog has more information on maintaining such large PostgreSQL databases.
We had already split a reporting database from our accounting database to minimize reads (more on this below), but at some point, even with mainly inserts and updates, the database didn’t scale anymore. This is when we decided to shard our accounting database into several accounting clusters.
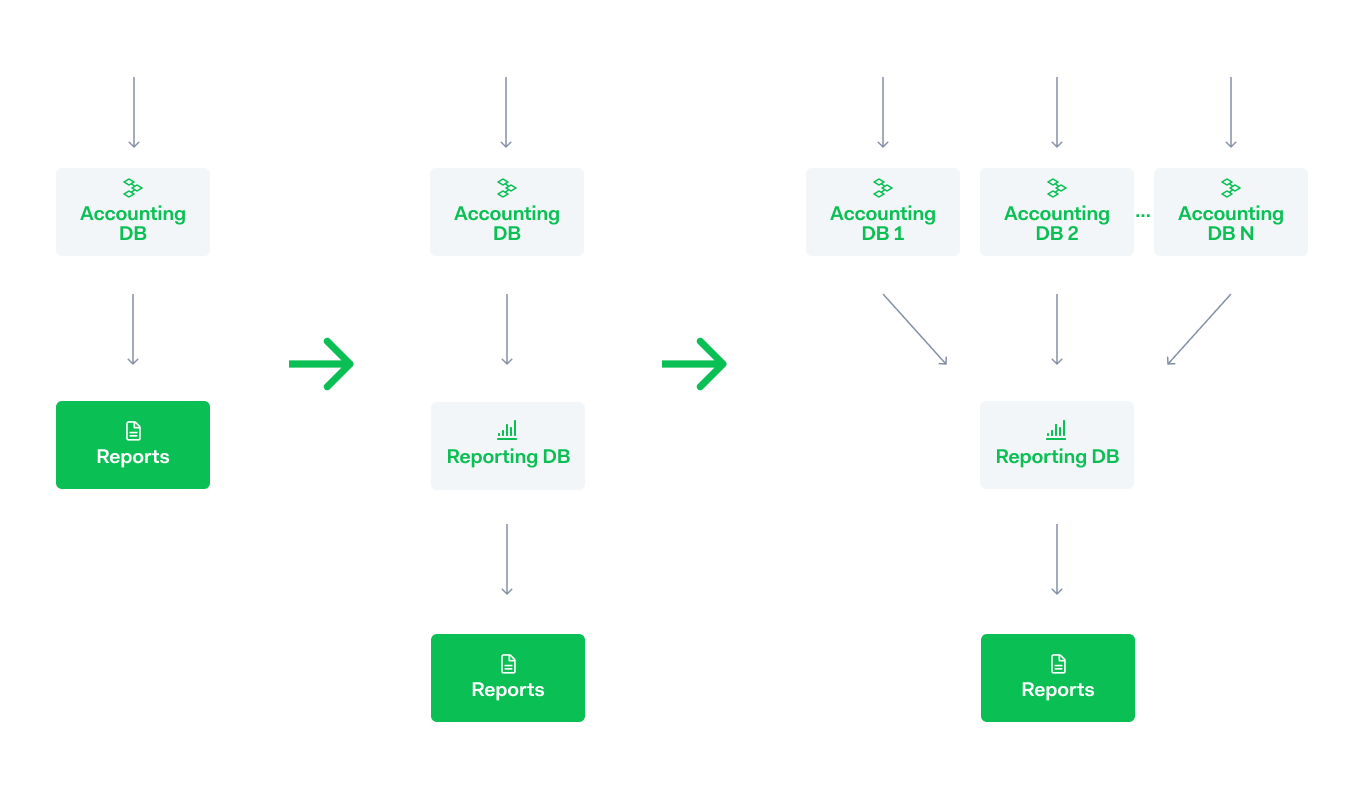
Sharding strategy
Now we have several accounting databases, or clusters, processing side-by-side. We considered incorporating domain knowledge into the sharding strategy, but, for several reasons, eventually decided to go for a simple round-robin strategy with some parameters we can adjust.
First of all, every rule we considered would bring its own problems. For example, if we would put each processing merchant in one database, you still need to go to every shard when you need aggregate data to send to our payment method partners. The same holds the other way around. If you split by payment method you still need to go to every shard when you need aggregate data on the merchant level.
Incorporating business logic would also complicate the routing, a round-robin strategy is very simple and robust and you do not have to think about balancing your shards. Finally, you lose a lot of flexibility. At the moment we can just add a new cluster whenever we need more capacity or remove one from the routing when we see strange behavior we want to investigate.
In the end, we decided the benefits domain knowledge routing would offer were not worth the loss of flexibility and increased complexity.
Migration
The migration to a sharded accounting database was quite painful. This was due to two things. First of all, the accounting logic in the code, pretty heavily embedded in any payments processor, working on the assumption there was just one accounting database. This had to be rewritten.
As an example, consider a payout to a merchant. This needs to come from one account. However, because you processed these transactions on different clusters, the money needs to be transferred from one cluster to the other in order to end up in the same account. To do this without compromising on the strict correctness requirement was quite difficult. In the end, we created several jobs and processes that use back and forth messages between the clusters to keep everything aligned.
The second complicating factor was that, if we received reports on processed transactions from our partners, we needed to match them to transactions in different clusters. Instead of parsing a file and matching it directly to the transactions, we introduced a two-step framework that would first parse a file and then split it into the relevant parts for each cluster. The second step was to match the relevant transactions within the clusters.
Whereas the first problem was solvable in a generic way, the reconciliation needs to happen for a lot of different very custom integrations so this was a real team effort.
Future challenges
From a scaling perspective, the risk that this approach introduces is that any process that depends on all accounting databases being up to date or available becomes a potential liability.
Historically, processes such as our back office (admin area) would interface directly with the accounting databases to display data or to make corrections. If one of the accounting clusters is not reachable this cannot be done anymore.
This is not a problem when there are only a few clusters, but as the number of accounting clusters grows, the chance of any of them being unavailable, planned or unplanned, grows with it. This means that instead of interacting with it directly, we need to do so with an intermediate that will mitigate this risk.
Also, rebalancing the clusters is something that is essential for traditional sharding (inside one database) but has not been implemented yet for this setup. If we add a new cluster, it will be empty while the old clusters keep growing. How do we avoid the original clusters becoming too big?
Connecting the edge services with the accounting system
Talking so casually about the downtime of our accounting clusters hints at different priorities in this part of the system compared to our edge systems discussed earlier. Whereas for the latter the priority was uptime, for the accounting systems we don't mind if they are down for a little bit as long as we can guarantee their reliability and consistency. For me, it was interesting to see how these systems are tied together.
In a very naive solution, these conflicting principles cause a conflict. The PAL would forward the payment to the accounting system to save it. If something goes wrong, do you still save the payments with a risk of inconsistent data, compromising on the consistency priority of the accounting system? Or do you stop processing, compromising on the uptime priority of the frontend? We went for a failsafe in between.
The Payment Processing Layer (or PAL, see part one) saves the payment in a local database and a separate process picks it up when possible. This process will run behind if we have doubt about whether we can guarantee consistency in the accounting or if an accounting database is not available but that will not impact the availability of the PAL itself. An added benefit of this setup is that if the PAL crashes, no payments are lost because the queue is stored in a database and not in memory.
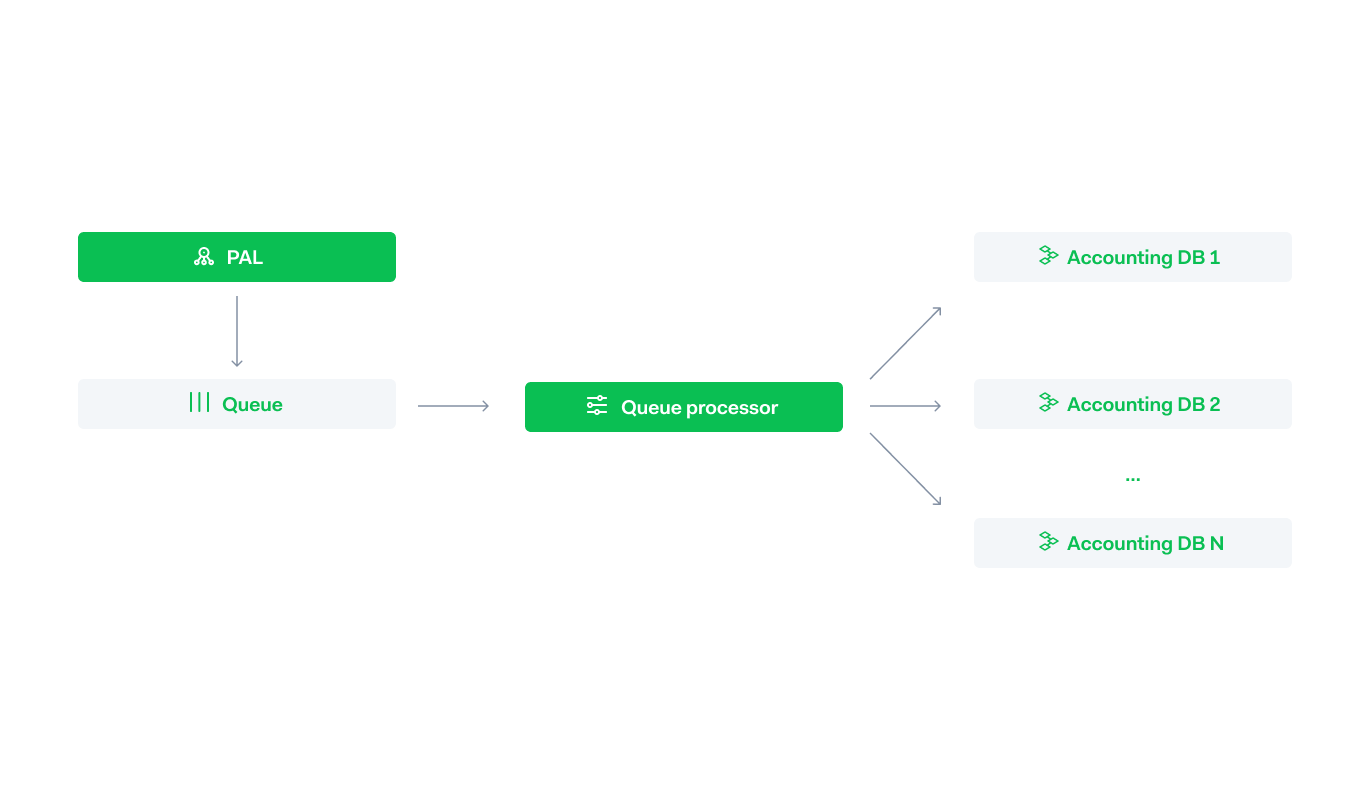
In another blog of ours, you can find more info on how this asynchronous queue between the different layers works.
Technology choices
The large accounting database and the short-lived queue both use a PostgreSQL database. This was again a pragmatic choice. In the beginning, the requirements on the system were not that high, so we went for a one-size-fits-all solution for databases. It might be that better solutions for queueing were available at that time or since, but we felt that it was not worth the additional complexity they would add to our system.
We have since been pleasantly surprised by how well PostgreSQL has performed for both use cases. At this point, we have dozens of local databases that can be instantiated dynamically at application startup and transactional databases of hundreds of terabytes running on the same technology.
This shows that specialized solutions that were designed to tackle specific problems that occur at very large scales might not be needed for smaller applications (or even quite large ones) while they often do add a lot of complexity. Of course, this is always a balancing act, because the solution might have nice specialized features and it is comforting to know that it will definitely scale.
Reporting
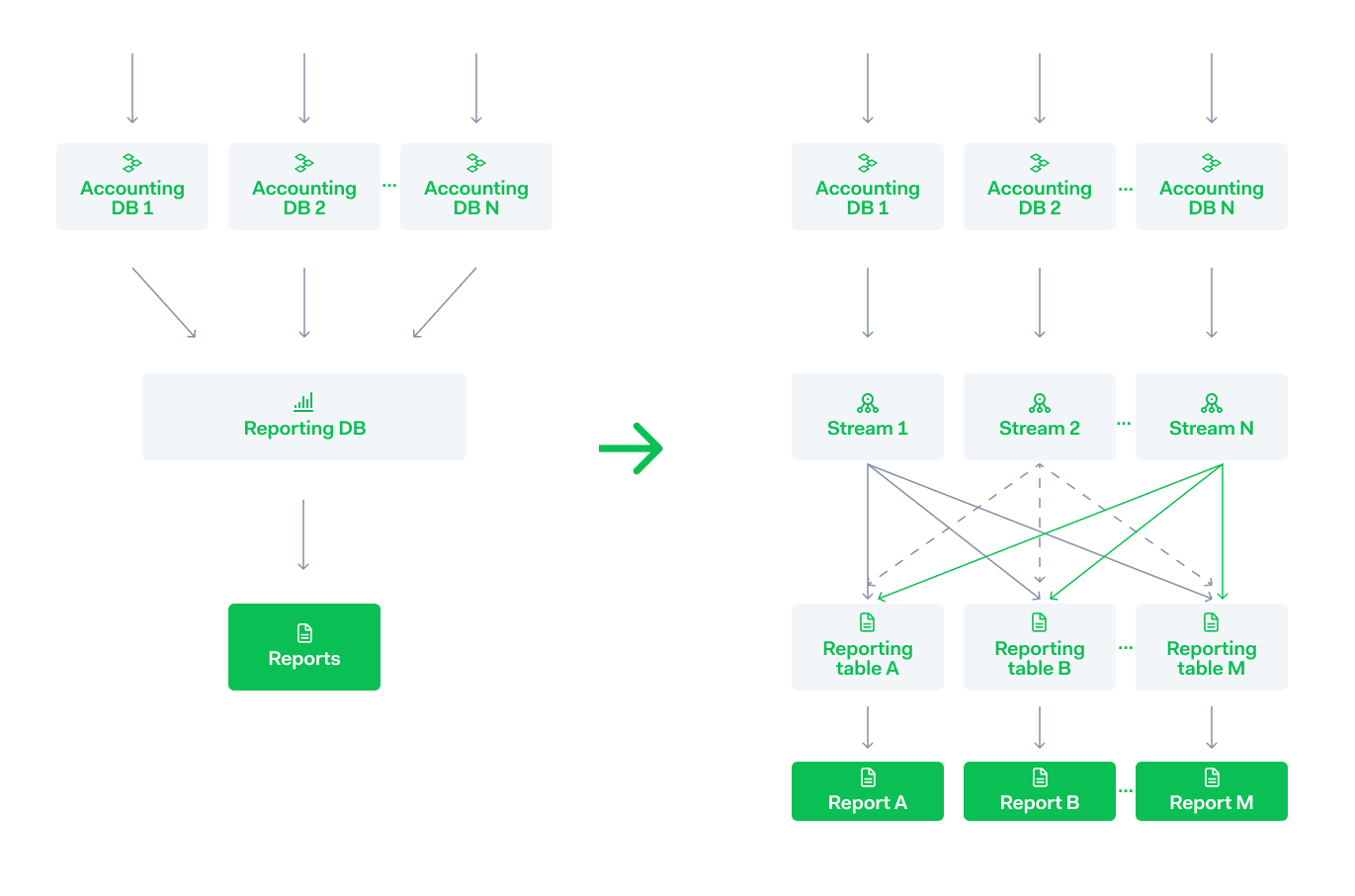
Creating separate accounting clusters creates a new challenge. Namely, how do you generate reports for every merchant and payment method every day from all these data sources?
We did have a reporting database where we saved the relevant data in a denormalized form. Initially created to minimize reads on the accounting database. However, relying on this might work for a while, but eventually, it would be just another bottleneck.
For this part of the system, the priority was throughput. We decided to stream the data from the clusters and to have specialized processes consume and preprocess the data for specific use cases. This way there are only a limited number of processes that have to read the stream and when the report is generated a lot of the work is already done.
The reporting tables can be split over as many databases as needed.
At the time a lot of different technologies were considered for this, especially Kafka. Our current processes were under quite some pressure so time was of the essence. We needed a high throughput, low latency streaming framework that could ensure exactly-once processing, even if processes crashed.
We scoped a lot of open source technologies but none offered the feature set we were looking for. For example, exactly-once delivery was not yet supported by Kafka.
On the other hand, we had a lot of familiarity with another technology that was close at hand and had proven very reliable. At this point, you might not be surprised to learn that this was PostgreSQL. For the same reasons, we used Java to write the application code on top of it.
Even though we did have to do some rounds of optimizations and we are missing some features, such as topics, we are happy with our choice. The setup stood the test of time even though traffic increased by an order of magnitude.
Even though we initially chose to write something ourselves, this is not a definite choice. In fact, there is an ongoing discussion whether this framework will allow us to scale another 20x or whether we should swap it out for an open-source solution such as Kafka. The 20x scaling factor is a rule of thumb we often use internally when designing a solution or determining whether we are still satisfied with it.
Analysis
For our data analysis setup, we did not build much in-house but chose to adopt industry standards. We run a Spark Hadoop cluster combined with Airflow. Deploying it on our own servers was an effort but now it is running smoothly. There isa blog about the initial shift.
Remarkable about the setup is that we still use our custom streaming system to verify all the information is actually consumed and correct.
With the Spark Hadoop cluster in place, the main struggle was to feed the results back into the synchronous systems.Herewe describe how we did this for monitoring. After this worked for that use case, we expanded it into a generic framework that can also score the machine learning models in real-time.
Conclusion
The focus of this blog was on payments processing but, as mentioned before, the concepts translate almost perfectly to the other business contexts such as the bank. This is because all systems have high availability and latency requirements on the edge services and strong consistency and reliability on the accounting layer. In the reporting and analysis frameworks, we tie all of the systems together.
This similarity in architecture, together with our conservative tech stack, allows developers to easily switch between teams. They already know the general design and the technologies used, even if the business context is completely different.
We hope that this blog made both our architecture and the way we arrived at it clearer. Perhaps it will also influence how you evaluate design choices for your own company in the future.
Technical careers at Adyen
We are on the lookout for talented engineers and technical people to help us build the infrastructure of global commerce!
Check out developer vacancies