
Article
A Deep Dive into Table partitioning 🐰 Part 2: Partitioning at Adyen
By Derk van Veen (Database Engineer) & Cosmin Octavian Pene(Java Engineer), Adyen
Recap
In our previous blog we discussed the basics of table partitioning in PostgreSQL. The main takeaway is that there are two strategies: inheritance and declarative/native partitioning.
Inheritance-based partitioning gives you the most freedom, but it is more limited with respect to partition pruning, and not transparent to the application. With declarative partitioning, you have to obey more rules, but it is completely transparent to the application and has better partition pruning capabilities.
Sharing some background Adyen context
We will introduce how we use partitioning at Adyen in this blog, and how we do simple maintenance tasks on partitioned tables:
Some of our tables are already over 20TB in size, so partitioning these tables in itself is already a challenge. When they are partitioned, we have to do simple tasks such as:
Adding new partitions
Adding indexes
Adding foreign keys
Dropping indexes
Detaching partitions
During all these tasks, it is important to not block the application; it has to be available 24 hours a day and all days of the year. We also have to take into account that we can’t block a table for more than a second. This additional requirement makes the maintenance much harder than originally expected. We love our jobs, but don’t like manual tasks, and because of this, we automated all maintenance tasks around partitions. For every partitioned table, we have a row in a table that holds the desired configuration in JSON format where we can specify:
How many free, unused partitions we would like to have available at all times.
Whether we would like to have additional check constraints on the partitions.
When we detach partitions.
When we drop partitions.
The use of the JSON format gives us a lot of freedom and flexibility for how we want to maintain our partitioned tables. We can add an option whenever we want without the need to change our configuration table. Beside these ever ongoing maintenance tasks, we also created a set of functions we can use to:
Create indexes on all children of a partitioned table.
Create foreign keys on all children of a partitioned table.
We are dedicated to the open source community at Adyen – we choose to opt for open source technologies where possible. To also contribute back to the community, we have decided to open source our partitioning functions. All functions mentioned in this blog are available in this public github repository
Partitioning an existing table
As a rule of thumb, we partition tables that might exceed the size of 100GB. Since we adopted the partitioning strategy only when we really had to, we already had, and still have a lot of tables exceeding this limit. We started looking at partitioning existing tables and found out that there are a couple of tools that can help with this – for example: pg_pathman and pgslice.
We tried these solutions, but at the end of the day, they didn’t work out for our specific use case. During the partitioning of these big tables we encountered multiple problems:
The queries selecting the existing data for a given partition took very long, and long running queries can have devastating effects on the overall cluster performance. They prevent effective vacuums, nullify the effects of the fill factor and might bring us in danger of transaction wrap around on some systems.
Selecting and filling the data for a partition took longer than the timespan for the partition. For example selecting the data for a daily partition would take longer than a day.
By moving the data around we would generate at least twice the table size in WAL. For a 20TB table this is a lot for additional replication, backup, etc. And this is only in the ideal situation; in reality, we would generate much more WAL.
Our working strategy for partitioning existing tables
Taking this challenge head on, we came up with a strategy to partition existing tables. This strategy is quite straightforward. It follows these basic steps:
Rename the existing table to <table>_mammoth
Create a table with the original table name
Add the original table as the first child
Add at least one more partition to accommodate the incoming data
As always, the actual process is not without some drawbacks. It is more complicated and we had to take the following into account:
Foreign keys to the original table
Triggers
Storage parameters

To make this process as smooth as possible, we scripted it. You can find the script in the partition_table.sql file in our partitioning functions repository.
This script contains a single function to partition an existing table into an inheritance based or a declarative partitioned table. Thank you very much Saiful Muhajir for creating these functions and starting our partitioning journey!
Let’s share some benefits and drawbacks of implementing this strategy:
Benefits:
It is performant: We are only manipulating the catalog, hence it is very fast.
We are not moving data around: We don’t move data around, and so we are not generating more than a few pages of WAL.
There is minimal locking: We only block the application for a very brief moment.
Drawbacks
We do not directly benefit from the partition strategy since all data still exists in a single partition.
We can only optimally benefit from partitioning when we don’t need the data in the mammoth partition.
Some fundamentals to understand for after partitioning
After partitioning your table – independent of whether this is inheritance or declarative – some things have changed: there is now an empty parent table and this parent has multiple children. From the application you can query the parent table to find any row in the children transparently. If you choose declarative partitioning, the partitioned table is even completely transparent for the application.
All of the child tables are still ordinary tables. Some of their properties will be enforced by the parent table, but from the child tables’ perspective they are just ordinary tables. This means you can query a single child table directly or change vacuum or fill factor settings for a child table. You may want the fill factor to be low when the partition is just starting to fill and has a lot of updates on it; so you can set it to a higher value after a week when the amount of updates on this partition decreases, and efficient storage becomes more important.
When a partition is relatively new, the data in the partition is most likely changing rapidly. At this moment, it might make sense to analyze this table more frequently. You can do this by setting one the storage parameter autovacuum_analyze_scale_factor for this child table. When the partition is no longer as frequently used you might want to increase this parameter. Only the properties enforced by the parent table cannot be changed. These are the properties, that based on inheritance principles, the children must have. This is true for all of the columns in the parent table and also the indexes on the parent table. At the end of the day, the only role of the parent table is to serve as a blueprint for the children.
This means a column or index that exists in the parent table cannot be dropped on the children. In order to understand what you can and can’t do with partitioned tables it is important to think about what is enforced, why it is being enforced and what can be changed independently.
Maintenance on partitioned tables
Maintenance on partitioned tables is slightly more complicated than for ordinary tables because of locking. On ordinary tables, there are multiple options directly available to prevent locking; like the concurrency option when creating an index. Many of these options do not apply to partitioned tables and you have to work around them. When you change something on the parent table, this should immediately be changed on all of the children as well. When the application ‘talks’ to the parent table, the actual work has to be delegated to the children. This is only possible when the children have at least the same characteristics as the parent table. With a lot of children and a high transaction load, you can imagine this instantaneous change to all tables might be a challenge.
On the other hand, the child tables are tables on their own and can have additional properties with respect to their parent(s). In this section we will look at the maintenance challenges and how we tackled them. Again, all the tasks handled in this chapter can be configured and performed automatically with the scripts and functions from our repository.
Child table management
The obvious management tasks for partitioned tables are attaching and detaching partitions. Creating a new partition can be done in different ways:
For inheritance based partitioning:
CREATE TABLE test_partition_30_40 (
CHECK ( id >= 30 AND id < 40 )
) INHERITS (test_partition);
Or in multiple commands:
CREATE TABLE test_partition_30_40 (LIKE test_partition INCLUDING ALL);
ALTER TABLE test_partition_30_40 ADD CONSTRAINT CHECK ( id >= 30 AND id < 40 );
ALTER TABLE test_partition_30_40 INHERIT test_partition;
And for declarative based partitioning:
CREATE TABLE test_partition_30_40 PARTITION OF test_partition
FOR VALUES FROM ('30') TO ('40');
Or in multiple commands:
CREATE TABLE test_partition_30_40 (LIKE test_partition INCLUDING ALL);
ALTER TABLE test_partition ATTACH PARTITION test_partition_30_40 FOR VALUES FROM ('30') TO ('40');
There is a subtle difference between the two methods, but this will be discussed in the next article on this table partitioning series. In the case of inheritance based partitioning, you alter the child to attach it to the partition. While in the case of declarative partitioning you alter the parent table to attach the child. If you want to drop a partition, you can drop the child table directly. But in case you want to keep the table but decouple it from the parent table you can detach it from the parent table.
For inheritance based partitioning:
ALTER TABLE test_partition_30_40 NO INHERIT test_partition;
Since a table can inherit from multiple parents you have to specify the parent.
And for declarative partitioning:
ALTER TABLE test_partition DETACH PARTITION test_partition_30_40;
In both cases the table test_partition_30_40 becomes an ordinary table without any inheritance properties. This is useful when you want to accommodate a cool down period before actually dropping the data, or if you want to rebuild the table inheritance structure.
Partitioned tables and indexes
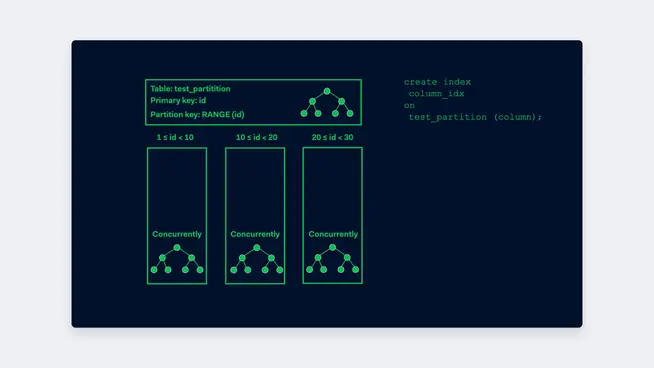
Another regular theme is the management of indexes. In the case of ordinary tables, creating indexes is not something we think twice about: We always create our indexes concurrently to prevent interference with the application. It takes a bit longer, but you’re not blocking the inserts, updates and deletes on the table. When we did the same to our natively partitioned table we got the error:
“ERROR: cannot create index on partitioned table "test_partition" concurrently”.
And according to the documentation: “Concurrent builds for indexes on partitioned tables are currently not supported.”
In PostgreSQL there is no such thing as a global index. Indexes do not span more than a single table. Even in the case of partitioned tables indexes are created for every child individually.
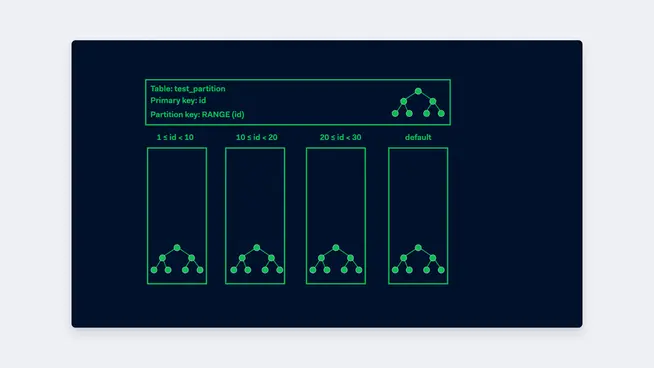
This also explains why the partitioning column has to be part of the primary key. When the partitioning key is not part of the primary key, there is no way for the database to enforce the uniqueness of the primary key. It is possible to create an index on the parent table, but this only enforces the creation of indexes on all of the current and future children. Understanding all of this makes it easy to find the solution for creating indexes on partitioned tables. You first create the index concurrently on all of the children and only after the last index on the children has been created, do you create the non-concurrent index on the parent table.
Unique indexes on partitioned tables A special situation is the unique index. Just like with the primary key, the partitioning column has to be part of the unique index in order for the database to enforce uniqueness over all partitions. But, sometimes, you want a set of columns to be unique without including the partitioning column. This might especially be true when you partitioned your table on a technical primary key and you want a set of other columns to be unique. Including the primary in the unique index would not make any sense, as it is already unique.
Here you face a difficult situation. There is simply no easy solution to enforce uniqueness over all partitions. You can create the unique index on all of the children, but you will not be able to create the unique index on the parent. As a consequence the availability of the unique index is not enforced on all of the children and has to be checked in some way. Our solution is to create a tablename_template table which we can use as a blueprint for all of the new partitions. This solution might work, but is error prone, and by no means enforced by the database.
Another downside of this situation is that you can never create a foreign key with this table as a parent. This requires a unique index on the table, which we simply don’t have here. Foreign keys with the children as parent are only possible in very rare circumstances. For example when the two tables are exactly equally partitioned.
The function to add indexes to a partitioned table is:
dba.partition_add_concurrent_index_on_partitioned_table()
And can be found in the script: partition_add_concurrent_index_on_partitioned_table.sql.
Dropping indexes on a partitioned table
Dropping indexes is much like creating indexes. Dropping an index requires an ACCESS EXCLUSIVE LOCK on the table, but fortunately we have the concurrent option to prevent this. Again, there is an exception for partitioned tables:
From the documentation: “ Lastly, indexes on partitioned tables cannot be dropped using this option.” By now we know the drill- We can first drop the indexes concurrently on all of the children and only then drop the index on the parent table, right? Well, actually not. Since there is an index on the parent table to enforce the existence of the index on all of the children, it is not allowed to drop this index on a child table. Long story short, if the index exists on the parent table you cannot drop the index concurrently.
To circumvent this problem you should not create indexes on the parent table. But if you don’t create the indexes on the parent table, the existence is not enforced for all of the children and you might run into performance problems some day. It is a trade off and you have to make your own decision here.
Creating foreign keys on a partitioned table
Creating foreign keys is much like creating indexes so we will keep it short. In order to prevent blocking the application, we add foreign keys always as “NOT VALID” and validate the foreign key afterwards. This will enforce the constraint from the moment of creation for new rows, and during the validation process all the existing data will be checked. To create the foreign key on a partitioned table, you first add the NOT VALID foreign key to all of the children, then you validate them all. Only then can you create the foreign key on the parent table.
ALTER TABLE test_partition_30_40 ADD CONSTRAINT fk_name FOREIGN KEY FOREIGN KEY (someId) REFERENCES reftable(someId) NOT VALID;
ALTER TABLE test_partition_30_40 VALIDATE CONSTRAINT fk_name;
ALTER TABLE test_partition ADD CONSTRAINT fk_name_parent FOREIGN KEY FOREIGN KEY (someId) REFERENCES reftable(someId);
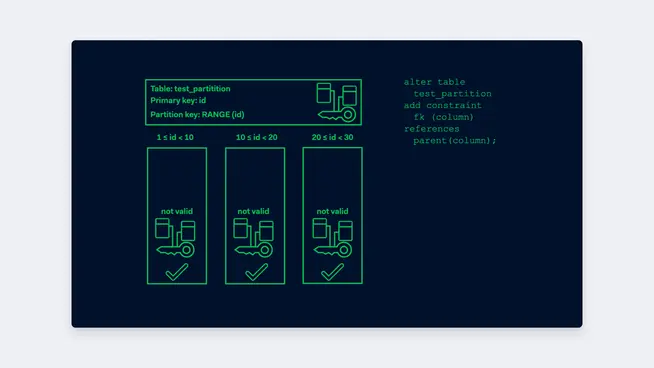
Adding the foreign keys to a partitioned table can be done with the function:
dba.partition_add_foreign_key_on_partitioned_table()
And can be found in the script: partition_add_foreign_key_on_partitioned_table.sql.
Automation
We love doing research about this topic and trying to find solutions for the problems we face. What we don’t like is manual interventions on all of our tables. That is too much work since we have a lot of partitioned tables and the numbers are growing by the week. Our solution is, as always, to automate it. In order to automate we need some way of keeping track of what we want. We have chosen a solution where we create a table in every database to keep track of the configurational demands. We also discussed a more centralized approach, but this was the easiest solution to implement. When you have to choose between two solutions, always take the easiest one. Our configuration table only has three columns
Schema name (text)
Table name (text)
Configuration (json)
By using a json column we have a lot of flexibility in what we want to configure. Every time we expand or change our options we don’t need to change the table definition.
Configuration for automation
We now have a table to hold our configuration wishes. In this section, we will describe how we use this table to actually do maintenance. We will only describe options here, you can find code examples in the repository. At the moment we have five configuration options for our partitioned tables. Let’s cover the first four for now. The last one will be covered in one of the later posts. The first four options are:
auto-maintenance
nr
detach
drop-detached
Enable auto-maintenance
We have the option to do automatic maintenance on partitioned tables. But we have a few use cases where, for historical reasons, the maintenance is done by the application. With this field we have the option to disable automatic maintenance. As a consequence we do not monitor the table, and from the DBA team, we take no responsibility with respect to this table.
Free, available partitions
The first question to always ask is: “How many free, available partitions do we need to feel safe?”. One nightmare is that when we need a partition to store data there will be no partition available. This in itself is not a big problem, but getting a call in the middle of the night to fix it? That is a big problem 😀. As a rule of thumb, we like to have at least three unused, available partitions at all times. We would also like to be able to accommodate at least another week of data. With this margin it is no problem if the maintenance scripts can’t get a lock on the table to do the maintenance a few days in a row. Of course we also have monitoring in place, but we prefer a good night sleep over creating partitions at night. When auto-maintenance is set to true we already make sure we always have at least three free, unused partitions available at all times. In the case of daily partitions, this is not enough to accommodate a week of data, so we use the nr option to specify we want at least ten partitions at all times. We consider a week as a critical value, so to be safe we create three more, just like all other partitions.
Detach and drop partitions
For some tables, we would like to delete the data after a given period. Maybe the table contains Personally Identifiable Information and we have to comply with the legal obligation to delete this data after a given period. Or maybe this table only contains data in transit, and we don’t need to store it for a longer period of time. In either case, detaching and dropping partitions is a cheap database operation. The table is simply marked as being gone. Of course, the operating system has to clean up the file system, but from a database perspective the table only has to be removed from the catalog. When you compare a catalog operation with a delete operation going through the entire table the difference can hardly be bigger.
In the configuration table you can specify when a child can be detached from its parent with the detach option. With this option we can specify any valid PostgreSQL interval, after which we will detach the partition. To select partitions eligible for detaching we look at the upper boundary of the partitions. After detaching the partition from the parent, the data is no longer accessible from the parent but still exists within the database.
All detached partitions are being registered in the dba.detached_partitions table including information we need to attach the table to the parent again: such as the original partition boundaries and the date we detached the partition. In order to actually drop the partition, you have to specify a drop-detached interval. This is a cool down period with a minimum of four days between detaching and dropping the partition. Automatically dropping tables is an anxiety inducing operation; doing it this way, we have a backup window in which we can very easily restore the data. With this configuration option you also have the possibility to increase the time between detaching and dropping the table.
We will wrap up this post here. We shared about the Adyen Way of Partitioning and some simple maintenance tasks that follow after partitioning - we also shared the partitioning functions repository that contains scripts we use for automating some of these tasks.
In the next post, we would delve into some of our tips for handling maintenance with the pressure of having the tables available at all times.