Reports
Optimizing payment conversion rates with contextual multi-armed bandits
By Rodel van Rooijen, Data Scientist, Adyen

You might have faced situations where you attempted to make a payment but for one reason or another, the payment was unsuccessful. This can be a frustrating outcome -- not only for the shopper, but also for the party that attempts to collect the funds.
At Adyen, we are familiar with how this feels. As such, one of our main focuses as a company is to ensure that the payment process goes smoothly. A key part of this is the tracking and optimization of the payment conversion rate, which is defined as the ratio between the payments initiated (payment was attempted) and the payments that succeeded (payment was successfully authorized).
Our problem
Companies that use our payment solution automatically useRevenue Accelerate, a product that optimizes conversion rates on their behalf. As part of this product, there are a lot of choices that Adyen has to make in the background before a payment can be successful. Optimizing the conversion rate means picking the choices that result in the highest likelihood of a payment succeeding. An example isStrong Customer Authentication(SCA), which is a process where a customer should authenticate (e.g. using a bank’s mobile app) before making the payment. For all the major (card) payment methods, this happens through a technology called3D Secure (3DS). Some banks require all customers to authenticate before a payment can be successful, while others might only do so for certain amounts. Other banks might not even be able to support 3DS. We help companies by taking away the responsibility to decide whether to require 3DS. In this scenario, RevenueAccelerate would optimize decision making.
The problem above sounds straightforward. We have two options: either enforce SCA or not. In reality, however, we have many more optimizations that we could apply. Other examples of optimizations that we apply are (but not limited to):
- For subscription payments, requesting an account (card) update from the card scheme and subsequently applying it.
- Optimizing the payment message formatting (ISO message), e.g. banks might prefer getting fields in a certain format (cardholder name, address fields, etc).
- Instantly retrying a payment, e.g. when a bank’s system is temporarily overloaded.
In total, this results in hundreds of optimizations that can be chosen. But from this pile, how does RevenueAccelerate pick the best optimization(s)?
The previous solution
We started by running experiments (in the form of A/B tests) for picking the right optimizations, which we optimized based on two features: the account (e.g. for Spotify) and the bank (e.g. ING Bank N.V.).
This resulted in a few problems:
- Small sample problem. Adding additional payment features (e.g. amount or transaction type) could result in small and thus insignificant A/B test groups.
- Experimentation versus exploitation. The result of an experiment is deterministic, i.e. if the underlying world changes then the experiment would have to be re-run again.
A bit of theory first
There are many solutions to a problem like the above. In our case, we went for a (Contextual) Multi-Armed Bandit set-up, for several reasons:
- Conceptually, it caters to both problems that were faced.
- The context (payment features) is very important to take into account, hence the contextual addition.
- While the world might constantly change, a full-fledged reinforcement learning set-up was out-of-reach from a technology perspective.
The setting is best described as a repeated interaction over several rounds. Formally, at each round:
- The environment (i.e. the real world) reveals a context (i.e. payment features).
- The learner chooses an action (i.e. an optimization).
- The environment reveals a reward (i.e. 0 for a non-successful and 1 for successful payment).
The goal of the learner is to choose actions that maximize its cumulative reward, which is the sum of rewards. An intuitive example here is playing a game that consists of one action and a reward (win or lose). A learner will start to choose actions. After a while, it learns which actions result in a win, and will continue only choosing those actions. In our use case, by interacting with the real world, we seek to maximize the number of authorizations and in turn -- the payment conversion rate.
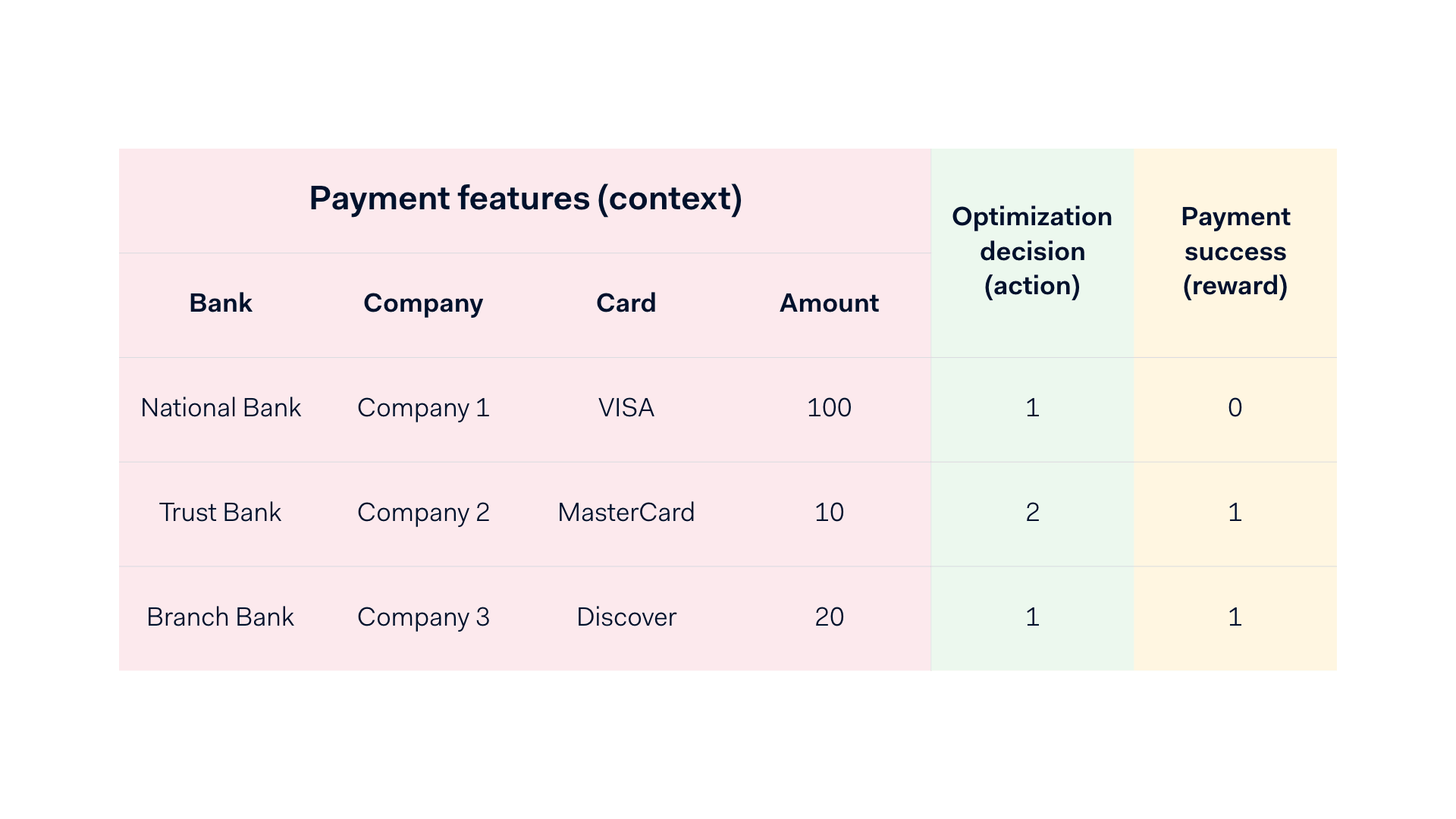
An example of our setting with contexts, actions and rewards.
Our conceptual solution
A classifier as oracle
To be able to define the probability of success for every chosen optimization we refer to the introduction of an oracle. We use the oracle (defined as a mapping from contexts and actions to probabilities) to predict the probability of authorization. Several different classification models were considered for playing the role of oracle, with the primary examples being logistic regression, random forest, and gradient boosting models.
In the end we chose to go for a specific implementation of gradient boosting models, namely XGBoost (eXtreme Gradient Boosting). There were several reasons for this choice, and the most prominent ones consider the size of the resulting model artifact (more on this later), as well as the performance of the classifier in terms of Area Under the ROC Curve (AUC), and the Area Under the Precision-Recall Curve (AUCPR).
Model features
- A range of numerical features, e.g. amount converted to EUR, card expiry date delta in days (between the payment date and expiry date).
- A wide range of categorical features (e.g. card type, bank, company, etc) for which we used Target Encoding (i.e. what was the conversion rate for a specific category value?)
- Each optimization decision gets its own dummy feature, i.e. each optimization has a feature of zero or one indicating whether it was applied on a payment. Note that every combination of optimizations is considered as one action.
Using historical data, the oracle can learn to infer the probability of success based on the past. There are however some pitfalls here. First of all, there is selection bias, as actions that were selected in the past might be chosen in a biased way (e.g. by only choosing one action and not exploring the other options). This can also cause certain actions to not have been observed in the past at all, making the inference for these actions problematic. Secondly, the underlying world might change from one moment to another (e.g. a bank might change their fraud system and suddenly block previously-successful payments), making historical inference not relevant any longer. And lastly, if the model is not fitted properly the probabilities might not make sense at all.
The action selection policy
To iteratively account for the above, we use one of the core principles of the bandit problem to our advantage. This is the exploration and exploitation of actions. When the model is certain about the best action, we should exploit it. If the model is uncertain we should explore more. This results in a policy, which defines a mapping between contexts and actions.
Our policy is constructed in the following manner:
- The best action is selected in an epsilon-greedy manner, i.e. the ratio of “best optimizations” (exploitation) is fixed to a static percentage α. Over time, this percentage can either be increased or decreased based on the performance observed.
- For the remaining percentage of 1-α, we pick an action from the remaining set of possible optimizations (exploration). To scale the remaining probabilities, we use a softmax function to convert the probabilities of success to scaled/normalized probabilities from which to pick actions from.
- In the end, this results in probabilities per action that sum up to 1. The ultimate action is then randomly chosen using these scaled/normalized probabilities as weights.
During the model training, we take the normalized probabilities (i.e. weights) into account by sample weighting the observations by the inverse of the probability of the action that was taken. In the example below, the model outputs the oracle probability, which results in normalized action probabilities after applying a policy. Finally the sample weights are derived being the inverse of the action probability, these are then fed back into the model training. This creates a feedback loop that has the frequency of model (re-)training.
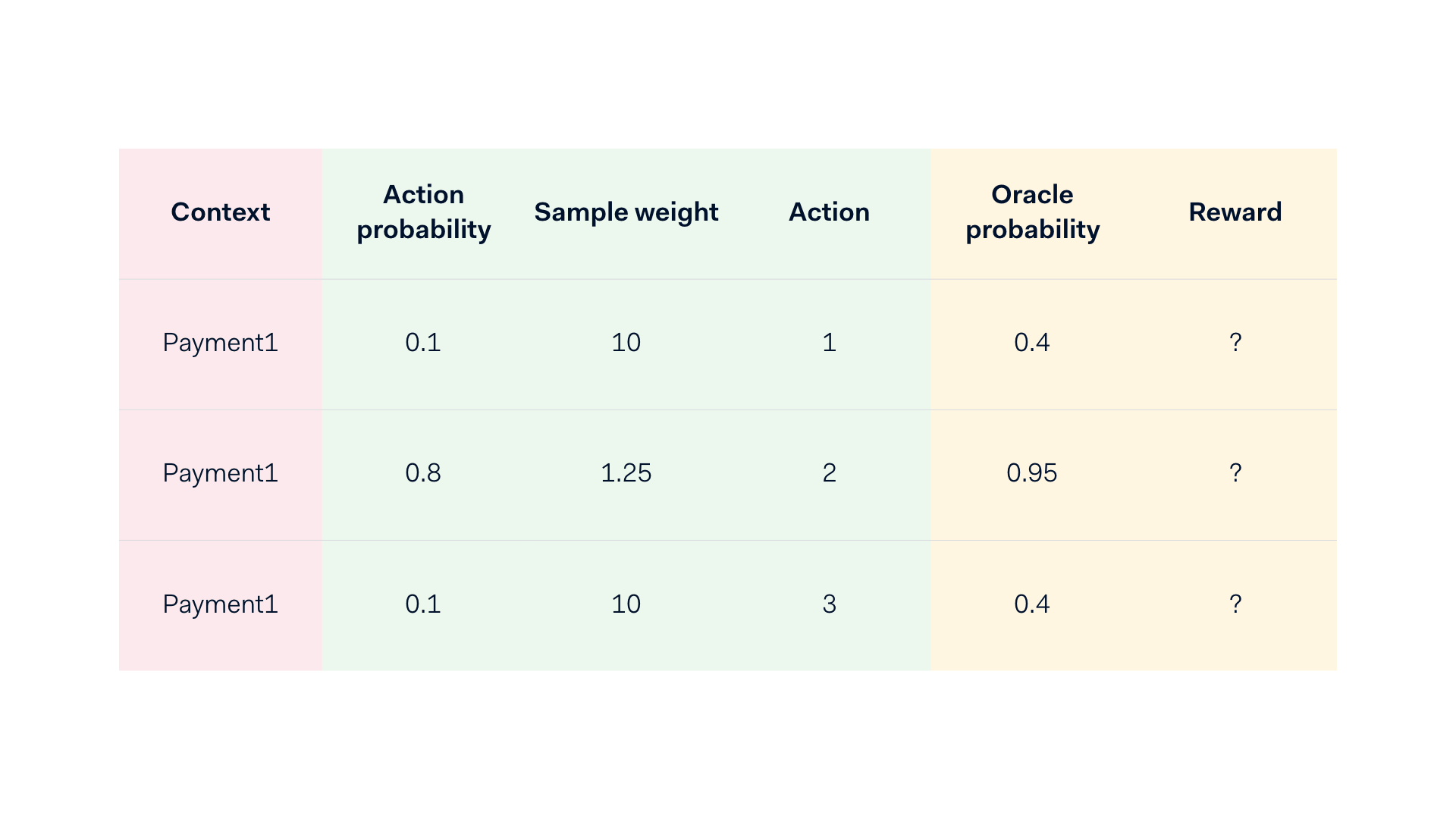
An example of an “exploded” context with its possible actions and action versus oracle probabilities.
The technical solution
The main challenge was getting the conceptual solution into a production setting. Namely, at Adyen this was one of the first attempts to get low-latency machine learning into production.
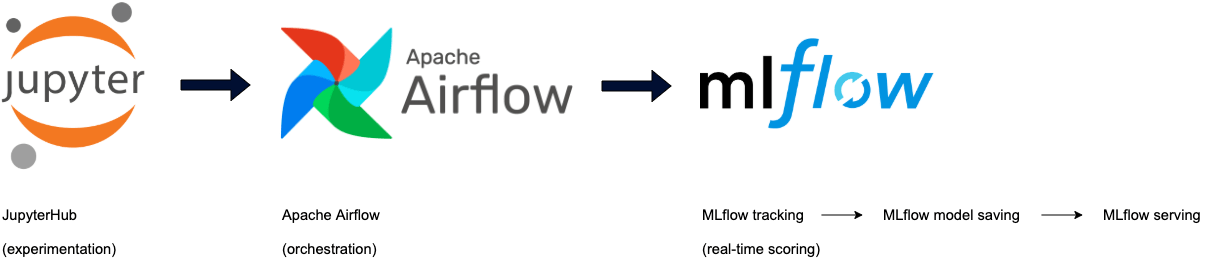
Experimentation
Our team leveraged Jupyter notebooks during experimentation. These notebooks run on a centralized data cluster, making model iterations easy and quick. As soon as a model is ready for deployment or further experimentation, the code is committed to the code repository where the model classes are defined with its own tests and orchestration.
Orchestration
The orchestration of model training (and hyperparameter tuning) happens through a scheduled Apache Airflow DAG which trains model(s) on a frequent basis, and automatically makes them available in a model artifact repository. We use MLFlow not only to save our models, but to also track any model metrics that were relevant during training. MLFlow enables us to save the model as a Python model, allowing us to incorporate the action selection mechanism (the policy) directly in the “predict” method.
Real-time scoring
There is a bit of magic going on here, and definitely worth a blog post on its own. To enable low latency model scoring, we have dedicated hardware that is responsible just for hosting our models. We use a combination of technologies to make this work, which we will not go into in this blog. In the end, MLFlow is the main driver behind making the cycle complete (i.e., saving, loading, and predicting).
We did face a few model-specific problems. One of the main problems we faced was the size of the model artifact, given that on the servers the model artifact is kept in memory to ensure low latency predictions. This, for example, causes problems when trying to train a big random-forest model. Such a model can result in a model object that is (several) gigabytes worth of data when saved.
Another problem was cutting the dependency with our codebase. Our aim was to have a light-weight package dependency to run the model(s). This was achieved by saving the model specific code (e.g. transformers, estimators and scoring objects) together with the model.
Results
The comparison between the previous solution and the new solution comprises the main part of the results. Ironically, we revert back to the A/B test setting to compare the old solution with the new solution. The measurements were taken over approximately a 2-month period, with weekly re-training (and policy evaluation) frequencies. In the results we will highlight two cases: i) An ecommerce-heavy company in the telecom sector; and ii) A streaming service company.
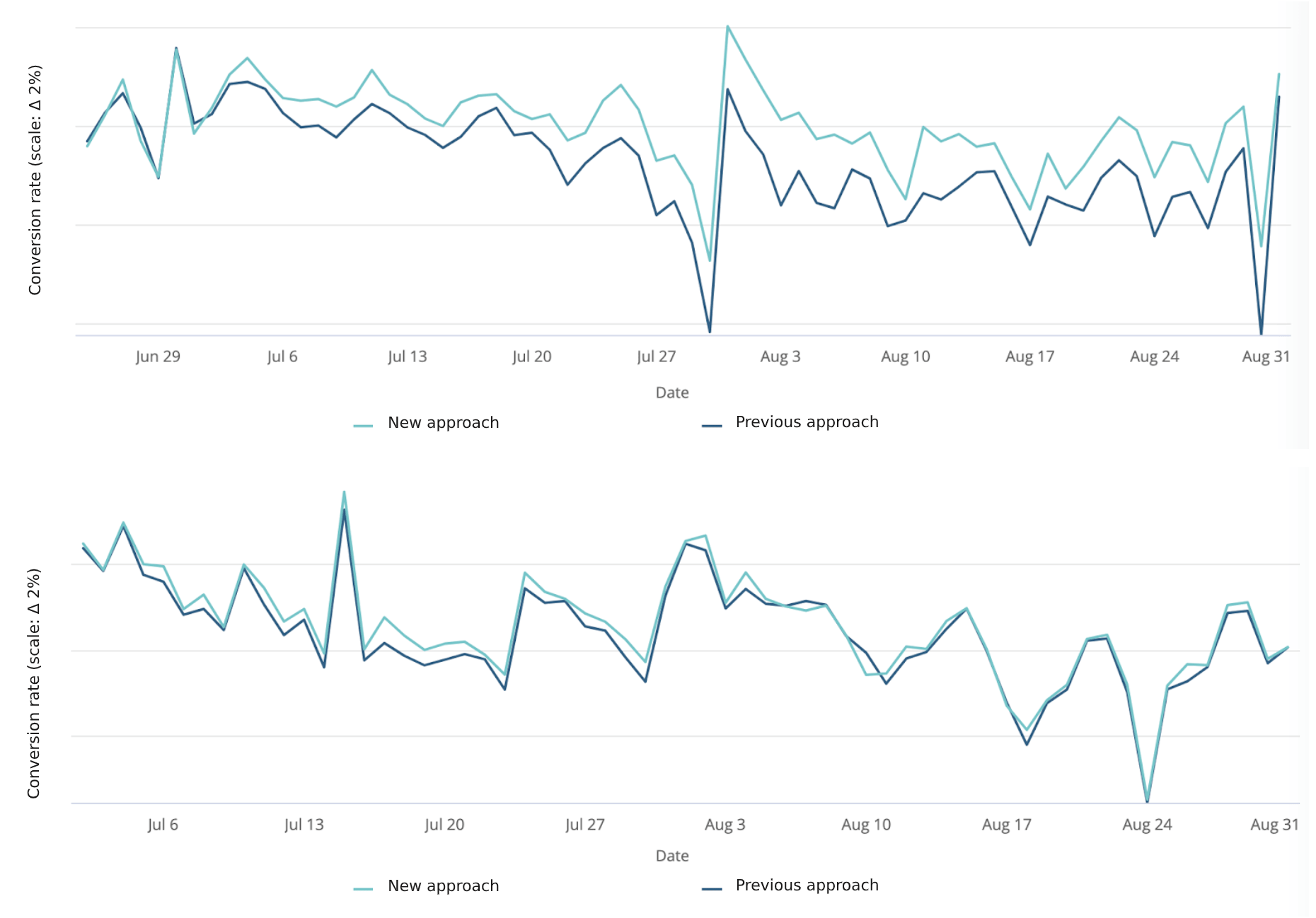
Conversion rates
As shown above, the solution needs time to improve its performance, but evidently starts outperforming after a while. In the second example, the performance seems to be varying over time. This is mainly due to real-world changes. As soon as the model is re-trained and the policy is re-evaluated, the performance gains are more evident. A reinforcement learning solution would probably pick up on these changes quicker.
Conclusion
At Adyen, we closely scrutinize our payment conversion rates. By optimizing our payment conversion as much as possible, we streamline the payment process while increasing the revenue that is earned by companies using Adyen worldwide. In this blog we have walked you through how we designed, built and deployed a low latency machine learning framework to boost payment conversion rates.
Technical careers at Adyen
We are on the lookout for talented engineers and technical people to help us build the infrastructure of global commerce!
Check out developer vacancies