Article
Test selection at Adyen: saving time and resources
By Mauricio Aniche, Testing Enablement Lead

If you work on a large-scale software system, odds are that a significant part of your build goes to test execution. It so often happens that you change one line of code but you get thousands of tests running, even though the majority of those tests don't even get close to that line of code.
This happens because build tools don't know much about what your tests really cover and because they are quite conservative: if you change a file in a module, it'll trigger all the tests of that module, all the tests of its dependencies, all the tests of the dependencies of your dependencies (your indirect dependencies), and so on and so forth.
Running all the tests we have available in our codebase for every code change is simply inefficient. Builds take longer to run, forcing developers to wait too long before their changes get merged (or before a test breaks). It also takes up too much of our CI infrastructure resources, which are large but finite. It's also less green as you are burning energy for literally zero business value. The situation gets even worse if one needs to start the whole platform to run the tests.
In practice, we know we don't have to run all the tests we have available in our codebase for every code change. The question then is: how to select which tests to run for a specific code change?
Test selection is a problem that software engineering researchers have been working on for decades now, but surprisingly there are no industry-wide solutions yet; therefore, companies might need to implement their own services for that. In this blog post, we'll:
Explain in a nutshell how our test selection tooling works.
Dive into the technical implementation details of our solution.
Show the benefits in terms of test case reduction and pipeline speed up.
How we keep the tool up and running reliably
The lessons we learned while building the tool.
In a nutshell
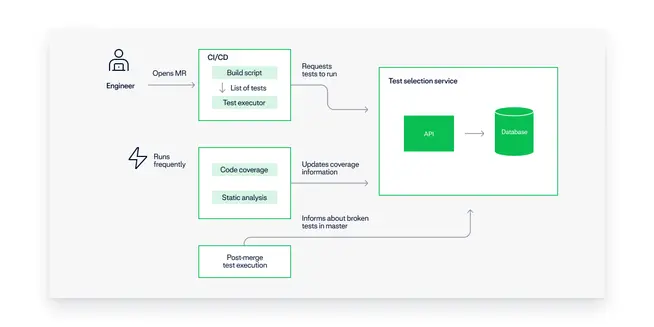
The entire process is depicted in the figure below. In a nutshell:
We recurrently collect fine-grained coverage information and build a database that contains all the tests that cover a specific class. This coverage information comes not only from traditional code coverage but also from other in-house code parsers that are able to link specific resource files to tests.
When the engineer opens the MR, the CI pipeline asks our test selection service for a list of tests to run.
Our modified test executors take this list into consideration and skip any test that's not on the list.
A much smaller subset of tests run!
Post-merge runs of the entire test suite make sure the test selection service has up-to-date information about what covers what.
Diving deep
Collecting fine-grained coverage
Traditional code coverage tools, like Jacoco, build up the coverage report containing the coverage of all test classes together. They don't often contain a list of which tests cover a particular class. Running the code coverage tool in a loop for every single test class in the codebase is highly inefficient and slow.
Luckily, Jacoco allows you to communicate with its agent via JMX. Therefore, we implemented our own JUnit listener that collects all the coverage information after each test class is executed. We send this pair of [test class, covered classes] to our test selection service, which then updates its current information.
Augmenting coverage
Pure code coverage may not be enough. Lots of files that are changed by developers aren't observed in code coverage. For example, configuration XMLs or YAMLs. We wrote some simple static analysis tooling that understands our code patterns and is able to produce links between non-java files and tests.
Some of these rules don't need static analysis per se, and you can identify them in a much simpler way. For example, we run a few tests written in JUnit on top of our deployment files. Our test selection framework allows us to write simple rules like "if something in this folder changed, run these tests".
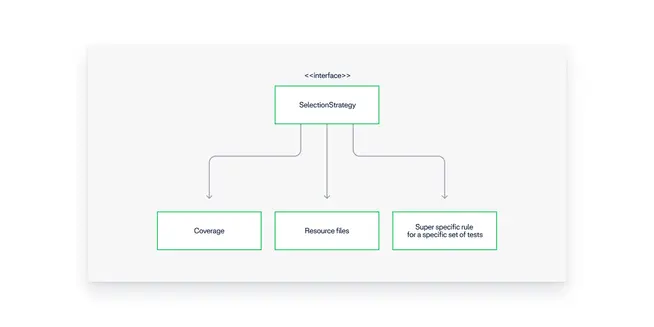
The test selection algorithm
The input for the test selection algorithm is the list of files that were modified in a particular merge request. This list is sent to our test selection by the CI.
With that list in hand, our algorithm works as follows:
Run all the tests of the Java modules of the modules modified.
Run all the tests that cover all the Java files modified (including tests in other modules).
Run all the tests we have based on either static analysis or hard-coded rules
As you can see, we don't really filter out tests for the specific modules that were changed in that merge request. Instead, we run them all. This decision comes with a trade-off. While we might be running tests that aren't needed, running them all ensures that our algorithm doesn't miss a test. It's quite hard for a platform team to know precisely how every single test in the code base works. Running all the tests of a given module reduces the need to create many specific rules. Note that we are talking here on the scale of hundreds of thousands of automated tests. The benefit is in avoiding running these hundreds of thousands, not a couple dozen.
We then run all the tests that have explicit code coverage on the changed files. It doesn't matter which modules they are in (or whether or not the module was modified in this merge request); if they cover a changed class, we run it.
Finally, we select all the tests for a file that we build a link to, either through static analysis, or through specific rules.
Running only the selected tests
The list of tests comes back from the test selection service to our build scripts, which then starts our Gradle test tasks.
Thanks to Gradle's and JUnit's flexible APIs, we have written our own Gradle plugins that read from this list and configure the test tasks with proper filters. This way only tests that we want are executed.
Skipping broken tests
Since we run only a subset of tests in each build, no matter how thorough your selection algorithm is, a broken commit will eventually make its way to the master branch. The larger your repository, the higher the likelihood this will happen. When that happens, it used to stop all engineers from being able to build, as a single test would break everyone's builds.
We monitor for possible broken tests in master through a series of post-merge execution jobs that run the entire test suite at the head of the master branch. If a test breaks in this post-merge job, we assume that this test will start to break all pipelines, even the ones that aren't related to that broken test.
Our test selection mechanism automatically excludes this test from merge requests, so that developers don't get blocked.
Any engineer can see the list of currently broken tests that are automatically skipped by CI in our internal backstage page.
It's worth mentioning that when such a test breaks, our system automatically notifies the developer that owns the broken test, and fixing it becomes a top priority for them.
Benefits
We ran a simple experiment in December 2023 where we took 69 current merge requests and ran them with and without test selection.
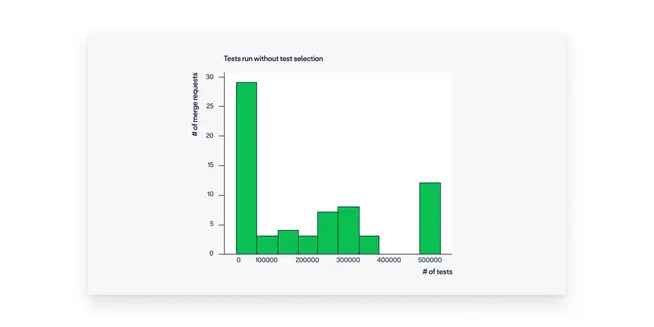
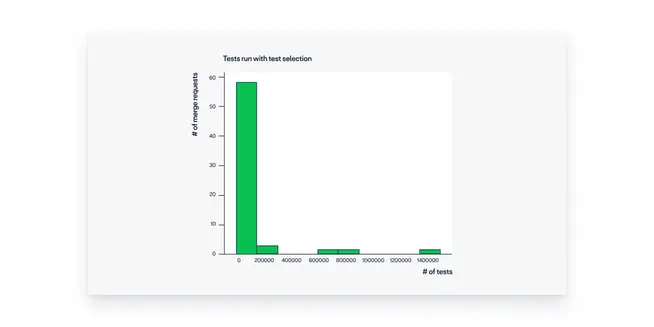
30x reduction in test cases executed
You can see the histograms below, showing the distribution of tests we ran with and without test selection in this sample. The average number of tests executed by builds without test selection was around 190k tests, whereas the average on builds with test selection was 6k, a 30x reduction!
Some concrete examples: one merge request went from 283k executed tests to only 1k. Another one went from 300k to 790 tests. We even saw one case where it went from 100k tests to merely eight tests (the test execution time of this particular merge request went from 25 minutes to a few seconds).
12x reduction in CPU time
In terms of test execution time, pipelines without test selection spent about 1 hour of CPU time whereas pipelines with test selection spent about 5 minutes, a reduction of 12x! In practice, this means our CI infrastructure can do more with the same resources.
Pipelines 10% faster
The total pipeline's duration was reduced ~10% on average (after all, we run tests in parallel).
We had cases where the pipeline was actually 30% faster, as the number of tests run went from hundreds of thousands to only a couple hundred tests. Faster builds make developers happy, of course.
(We only realized later that we did not turn off our build caches for these experiments. This means that the builds with test selection might have not benefited as much from the cache as much as the original build. Our day-to-day observations show that pipelines do get significantly faster because of test selection.)
No broken tests slipping into master
Another important question to answer is: if there's a test that should break in a merge request, would this test be selected? We picked 20 merge requests (that were executed without test selection) with broken tests and provided them as inputs to our test selection algorithm. In each case, the algorithm would have correctly selected the broken test as part of the tests chosen to run. Although 20 is a small number, after having the tool running for many months, we empirically observe that the number of times the tool makes mistakes is negligible in comparison to the number of pipelines it runs on (the number of pipelines we run a month is on the scale of tens of thousands, and the number of missed test runs is not even a handful).
These numbers are far from being precise, as there are just too many moving pieces we can't control, such as the use of Gradle caches or the load of our CI servers throughout the experiment. Moreover, our tooling (as well as our build system) has evolved significantly and these numbers probably don't represent the precise quantitative benefits we get, but they are still nice indicators of the improvement that test selection brings to our pipelines.
Keeping it up and running
Test selection has already proven to provide quite a boost in terms of efficiency. With the tool deployed and running on 100% of our merge requests, making sure that the tool is reliable is of the utmost importance.
Perhaps the most important decision is to never allow the build to break in case the test selection service is down. It's best to delegate back to our build system to select the tests and have slower builds for an interval of time rather than stopping the entire company by having no builds at all.
Observability is also key, as we need to know if the service is failing as soon as possible. We apply standard monitoring tooling to our test selection, paying attention to metrics like error spikes or a drop in the number of pipelines that run with test selection.
It also sometimes happens that engineers ask why some tests didn't run in their pipeline. It's our duty to explain to engineers why that happens, especially in cases where a test that was supposed to break didn't run. All recommendations that are made by our tooling are logged. Our CI logs produce a unique key that we can use to understand precisely what our algorithm recommended. We have a page in our internal backstage tool that visualizes every step of the algorithm and which tests were selected at each stage.
In addition, our Gradle plugins and JUnit listeners also produce logs explaining why they skipped (or not) a test and what list of broken tests they had internally at the moment of the decision. During debug sessions (which happened a lot at earlier stages of the tool), we could easily understand if the test was skipped correctly or not.
The accuracy of the tool also depends on the soundness of its data. Code is changing all the time, and we need fresh coverage information as fast as possible. The code coverage collection jobs run in a loop. With our currently allocated resources, we see that a data point can be about one hour old, which doesn't seem a problem in practice.
Lessons Learned
We have been on a 1.5 year long journey, from prototyping to deploying our test selection tooling successfully on all our pipelines, and we have learned a few things along the way.
You won't have full coverage information
First, you won't ever have coverage information about every single file in the monorepo. The number of (non-java) files that are created is massive, and you won't be able to catch up with enough rules or static analysis to cover them all. In earlier versions of our system, we took a more conservative approach of delegating back to the build system in case the merge request contained a file we had no information about. As a result, around 50% of the merge requests were not using tet selection. We solved these cases by introducing the rule that we run all the tests of the modified modules. As even non-java files belong to a module, it's safer to assume that its module will be the one containing tests for that file.
Have an exclusion list ready for quick fixes
At the beginning, especially when we were still maturing our algorithm and the quality of the data, we benefited from having an easy to modify exclusion list that would simply not do test selection for specific modules or if specific files changed. That allowed us to safely learn from bad recommendations while being certain that the lack of accuracy of our algorithm wasn't letting broken changes be merged into master.
Precision versus simplicity
Deciding how strict you want to be in the selection is also an important decision. For example, we could have opted for an even more specific algorithm that would select specific test methods and not the entire test class. We could have tried to do selection in the tests of the modified modules instead of running all of them. That would have further reduced the number of tests we selected. There's a fine balance between the complexity of the tooling you'd like to build, how much you really need to save in terms of costs, and your error budget as more complex tools might make more mistakes. All-in-all, we believe we have found the right trade-offs for the type of software we build.
Get ready to handle broken tests in master
Given that test selection is bound to make mistakes from time to time, especially at first, it's important to be prepared for broken tests that get to the master branch. In our case, we implemented the mechanism that skips tests in CI that are broken in master. This ensures that if a mistake happens we don't prevent developers from continuing to work. As owners of this tool, whenever we notice that a broken test landed on master due to a tooling error, we try as much as possible to assist the engineer that wrote the MR that introduced the broken test. We investigate each incident and see what we can improve in the tool so that it doesn't happen again. After so many iterations, our tool is now quite reliable and rarely makes mistakes. The frequent post-merge full execution of the test suites also ensures that no deployments happen in case a test is broken.
Conclusions
Test selection is an effective mechanism to save time and costs while maintaining rigorous pipelines. To sum up:
Running tests have a cost. Running (thousands of) tests that aren't useful for a particular change is a waste.
Test selection is about carefully selecting which tests to run for a given change.
We implemented our in-house test selection tool that uses a combination of code coverage, static analysis, and other rules to determine which tests to run.
We observed a reduction of 30x in the terms of tests we run, a 12x reduction in CPU time, and a 10 minute decline in average overall pipeline run times.
Being able to explain why the algorithm selected such tests is important, especially when a test that was supposed to run didn't.
It was a long journey from prototype to fully live and accurate enough, due to the many special cases we had to accommodate for.
Further reading
If you are interested in test selection, here's a few other interesting blog posts and papers:
Facebook has written about its predictive test selection algorithm that uses machine learning. The model basically learns from past test executions. This blog post has an interesting section also describing why letting your build tool decide what tests to run isn't efficient.
Milos Gligoric, a researcher at The University of Texas at Austin, has published numerous papers on test selection over the past decade. One of his key contributions is shifting the focus towards coarse-grained coverage and expanding the scope beyond traditional code coverage metrics. In 2015, he began developing a test selection tool called, Ekstazi, which is available on Github.
Acknowledgments
The Test Selection tool is maintained by our Testing Enablement team: Mauricio Aniche, Dmytro Zaitsev, Vadym Zakharchuk, Bhathiya Jayasekara, and Ali Kanso. Our amazing CI/CD and Build tools teams also helped us tremendously during this entire time.