
Article
Data Agent Benchmark for Multi-step Reasoning (🕺 DABStep)
Alex Egg (Adyen), Martin Iglesias (Adyen), Friso Kingma (Adyen), Andreu Mora (Adyen), Leandro Von Werra (HuggingFace), Thomas Wolf (HuggingFace)
👉🏽 You can access DABStep with this link here: https://huggingface.co/spaces/adyen/DABstep
Language models are becoming increasingly capable and can solve tasks autonomously as agents. There are many exciting use cases, especially at the intersection of reasoning, code, and data. However, proper evaluation benchmarks on real-world problems are lacking and hinder progress in the field.
To tackle this challenge, Adyen and Hugging Face built the Data Agent Benchmark for Multi-step Reasoning (DABstep) together. DABstep consists of over 450 data analysis tasks designed to evaluate the capabilities of state-of-the-art LLMs and AI agents.
Our findings reveal that DABstep presents a significant challenge for current AI models, with the most capable Reasoning-based agents achieving only 16% accuracy, highlighting significant progress to be made in the field.
DABStep requires AI models to:
dive in details of data and be rigorous (no hallucinations)
reason over free form text and databases
connect with real life use-cases (not just math or code)
In this blog post, we’ll cover the design and construction of the benchmark, explore evaluation results, and discuss the significant gap between current models and the ability to solve complex data analysis tasks effectively.
Motivation
Data analysis is both an art and a science that requires technical skill, domain knowledge and creativity, and thus, it’s rarely straightforward. Even seasoned data analysts face challenges like:
Simple but time-consuming tasks: The sheer volume of even simple tasks often turns straightforward analysis into hours of repetitive work.
Complex context and high cognitive load: Some tasks require analysis to juggle intricate domain-specific knowledge, making them both time-intensive and mentally draining. For example, (1) reading distributed, nested, and complicated documentation; (2) analyzing data; (3) reasoning over results; and finally, providing recommendations that will steer the direction of the business.
Technical acumen: analyzing data could be a simple task provided the data is of high availability, high quality, and ready-to-serve. Unfortunately, this is rarely the case, and analysts need technical depth to create pipelines that consume, transform, and serve data. Data analysts often take on tasks pertaining formally to data engineering.
At companies like Adyen, analysts tackle a spectrum of problems, from routine queries to complex workflows requiring creativity, precision, and iterative reasoning. Access to a capable data analysis agent that can automate simple and repetitive tasks and assist with complex tasks would allow analysts to work faster, reduce mental strain, and focus on solving more impactful problems. That would be a pivotal moment for many industries that need data analysis and insights, such as finance.
Recent advancements in agentic workflows — where LLMs equipped with tools independently execute multi-step tasks — have shown tremendous promise across domains like coding, open QA, software engineering, and even Kaggle competitions. These systems aren’t just theoretical; they've been driving real-world productivity gains.
So, the question becomes: Can agentic workflows reshape the way we approach data analysis?
Introducing DABstep
Progress in machine learning is fueled by high quality benchmarks that yield reliable progress signals. Thus, we are excited to introduce the Data Agent Benchmark for Multi-step Reasoning (DABstep), a new benchmark for evaluating and advancing agentic workflows in data analysis.
Here’s what makes DABstep unique:
Real-world use cases: Built on 450+ real-world tasks extracted from Adyen’s actual workloads. These tasks are not synthetic toy problems; they reflect challenges analysts face daily, setting DABstep apart from other benchmarks like DS-1000 or DS Bench*.
Balancing structured and unstructured data: These tasks require advanced data analysis skills to navigate structured data and understand multiple datasets and documents captured in unstructured data.
Simple setup: Unlike benchmarks such as SWE-bench or MLE-bench, which require complex configurations, DABstep is simple to use. Generating answers with a model only requires access to a code execution environment, and participants can submit answers directly to a leaderboard for automatic evaluation.
Factoid evaluation: Tasks have been designed to be evaluated objectively, and as such, the evaluation of the task output will always map to a binary outcome, right or wrong, without interpretation.
Multi-step complexity: DABstep tests systems across a spectrum of analytical tasks, from routine queries to multi-step, iterative workflows. Unlike benchmarks focused on isolated questions, DABstep challenges models to engage in end-to-end agentic reasoning across diverse, practical tasks.
How does DABstep achieve all this and remain a simple to run benchmark? Let’s take a look at its design!
What’s inside the DABstep?
DABstep has been designed for low-barrier usage, quality evaluation and increasing difficulty levels. To this end, we are opening up the following items as part of DABstep: Datasets, Tasks, Evals, Real-time Leaderboard and Baselines.
Data
One of the biggest challenges analysts must overcome, when working on real-world problems, is balancing domain knowledge and technical skills. To this end, DABstep contains both unstructured and structured data to measure domain knowledge and technical skills respectively.
Table 1 shows a snapshot of some of the dataset we are releasing with the benchmark.
payments.csv
Description
Payments dataset of 138k (anonymized) transactions with various signals around fraud and risk use-cases.
payments-readme.md
Description
Documentation for the Payments dataset
acquirer_countries.csv
Description
Table of Acquiring Banks and respect Countries
fees.json
Description
Extensive dataset composed of 1000 Scheme Fee structures.
merchant_category_codes.csv
Description
Table of Merchant Category Codes (MCCs)
merchant_data.json
Description
Table describing merchants
manual.md
Description
In finance, business contexts are often outlined in extensive handbooks from networks, regulators, and processors. For the first version of this benchmark, we have created a markdown file (manual.md) that distills essential business knowledge into a precise yet simplified format for solving tasks accurately.
Table 1: The benchmark is composed of various datasets across various tasks including the financial payments sector.
Some of the structured datasets include CSV and JSON files representing real-world data, such as transaction telemetry and business metadata (e.g., merchant category codes). Additionally, we have unstructured data such as documentation, lengthy manuals, and detailed handbooks that, for example, are issued by networks, regulators, and processors.
All of these datasets were extracted from real-world tasks at Adyen.
Tasks
Based on the new datasets included in DABstep, we are releasing several tasks with increasing difficulty levels designed to test an AI agent’s accuracy.
Each task contains the following items:
A question that proposes a challenge to the analyst.
A level encapsulating the difficulty of the task.
Guidelines on how to format the answer to meet the specifications of the evaluation.
None of the tasks can be solved with 1-shot of code; in other words, they cannot be solved by reasoning alone, but rather, they require sequential steps of iterative problem-solving. For example, at the minimum, the agent must at least know what columns exist in the respective dataset to answer a question. This is contrasted with popular benchmarks like GAIA, MATH and SimpleQA, where it's possible to answer multiple questions with 1-shot of code correctly.
Two example tasks are shown in Figure 1, and an example human-made reference solution is shown in Figure 2.
Question: Which card scheme had the highest average fraud rate in 2023?
Guidance: Answer must be the name of the scheme.
[LLM/Agent Loop…]
Answer: SwiftCharge
Question: For the year 2023, focusing on the merchant Crossfit Hanna, if we aimed to reduce fraudulent transactions by encouraging users to switch to a different Authorization Characteristics Indicator through incentives, which option would be the most cost-effective based on the lowest possible fees?
Guidance: Answer must be the selected ACI to incentive and the associated cost rounded to 2 decimals in this format: {card_scheme}:{fee}.
[LLM/Agent Loop…]
Answer: E:346.49
Figure 1: On the left is an example Risk/Fraud question from the Easy Set. Solution requires referencing at least 2 data sources and 3-shots of code. On the right is an example Scheme Fees question from the Hard Set. The solution requires referencing at least 2 data sources and multiple shots of code. The included answers are just for demonstration purposes and are withheld from the dataset.
Levels
The benchmark consists of two difficulty levels:
Easy Level: These tasks serve as warm-ups, helping to verify setups, integrations, and research direction. They typically require only a single structured dataset and minimal contextual knowledge. On average, humans achieve a 62% baseline on these tasks after 3+ hours of work, while a Llama 70B zero-shot prompt can exceed 90% accuracy.
Hard Level: These tasks demand a more complex approach, involving multiple structured datasets and domain-specific knowledge. Unlike the easy level, they typically cannot be solved with a single-shot code generation and require multiple steps of reasoning.
As an example of a multi-step reasoning problem, Figure 2 shows a snippet of the human-made reference solution to a Hard Level task. Overall, it is broken down into four(4) sequential steps including the development of various support macros. In order to code this solution, the agent would have to have specific domain knowledge and the ability to work in sequential steps of iterative reasoning.
def get_total_volume(df: pd.DataFrame, merchant: str, month_name_list: list[str]) -> dict[str, float]:
month_to_volume = {month_name: 0 for month_name in month_name_list}
for month_name in month_name_list:
filter_condition = (
(df.month_name == month_name) &
(df.merchant == merchant)
)
month_to_volume[month_name] = float(df[filter_condition].eur_amount.sum().round(2))
return month_to_volume
def get_total_fee(payment_segments_with_fees: pd.DataFrame) -> float:
total_fee = payment_segments_with_fees.fee_amount.sum().round(2)
return total_fee
def append_total_fee_per_segment(payment_segments_with_fees: pd.DataFrame, fees_df: pd.DataFrame) -> pd.DataFrame:
payment_segments_with_fees["fee_amount"] = 0.0
for idx, segment in payment_segments_with_fees.iterrows():
fee_amount = 0
for fee_id in segment['fee_id']:
# Filter the specific fee
curr_fee = fees_df[fees_df.ID == fee_id]
fixed_amount = curr_fee.fixed_amount.values[0] if not curr_fee.empty else 0
rate = curr_fee.rate.values[0] / 10000 if not curr_fee.empty else 0
# Compute fee based on transaction count and eur_amount
# Code Truncated
old_cost = compute_total_fee_cost(
payments_df=payments_df,
fees_df=fees_df,
merchant_data_df=merchant_data_df,
merchant_name=merchant,
months=MONTH_NAMES,
)
merchant_data_df.loc[merchant_data_df.merchant == merchant, "merchant_category_code"] = target_mcc
new_cost = compute_total_fee_cost(
payments_df=payments_df,
fees_df=fees_df,
merchant_data_df=merchant_data_df,
merchant_name=merchant,
months=MONTH_NAMES,
)
answer = new_cost - old_cost
answer = round(answer, 6)
Figure 2: The 220 line reference solution to a question in the Hard Set: “If the merchant {merchant} had switched its MCC code to {target_mcc} prior to the start of 2023, how much of a difference in fees would they have to pay for the year 2023?” The solution requires multiple steps of inductive reasoning difficult for 1-shot code generation.
Generalization
Some quick comments on how we are hoping to encourage generalization with the benchmark.
Symbolic Reasoning: In the spirit of GSM-Symbolic, tasks have been exploded in cardinality using permutations of time ranges, merchant names, etc. The rationale is to remove the chance of “lucky guesses” and validate core reasoning (repeatability of reasoning) and generalization.
Hidden Test Set: We have opted not to divide the dataset into validation and test sets and are only releasing a heldout test set. This is because a data analyst agent should be able to generalize across various analysis tasks not per se captured in this benchmark version.
Dev Set: Given this hard generalization setting, the scale of the benchmark (450 questions), and in the spirit of developer friendliness, we have also released a dev set, which is a representative subset of the full test set, including answers. The spirit of this dev set is to allow researchers to configure their E2E submission pipeline locally, including evaluation and fast feedback loops, and then submit to the leaderboard proper.
To test worldwide generalization, DABstep should not be benchmarked alone, and it should be seen in combination with other benchmarks that test overall generalization and problem-solving (e.g. MMLU, SuperGlue, GPQA).
Evaluations
For simplicity, we have opted for a factoid-based answer evaluation system. This means that answers to benchmark questions should be simple words, numbers or multiple-choice combinations. This allows for unbiased, scaled and model-free evaluations. (This is as opposed to natural language answer submissions evaluated by a judge LLM)
Given that, we didn’t intend answer formatting to be the focus of the benchmark. To that end, we implemented a series of flexible evaluation methods that ensure that the focus remains on the accuracy of the answers rather than their formatting. As examples, we use adaptive tolerance to compare numerical values, allowing for variations in precision and formatting. Strings are normalized and compared using fuzzy matching with a similarity ratio threshold. Lists are evaluated element-wise after normalization.
Real-time leaderboard
DABstep features a real-time leaderboard powered by Hugging Face, where participants can submit their answers to be graded instantly. You can see your standing against others around the globe with instant feedback.
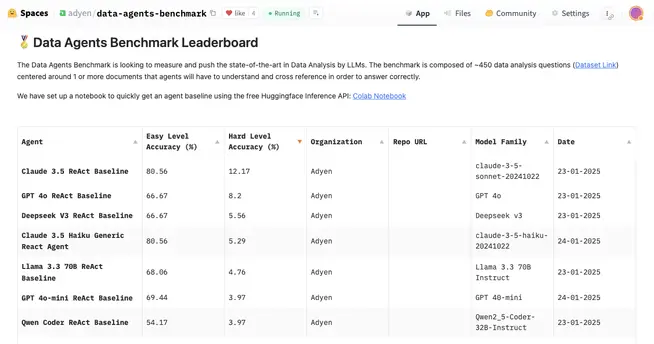
Snapshot of the leaderboard with the most ranked submissions. Link: DABstep Leaderboard
Baselines
We are providing a set of baseline evaluations across popular open and closed models.
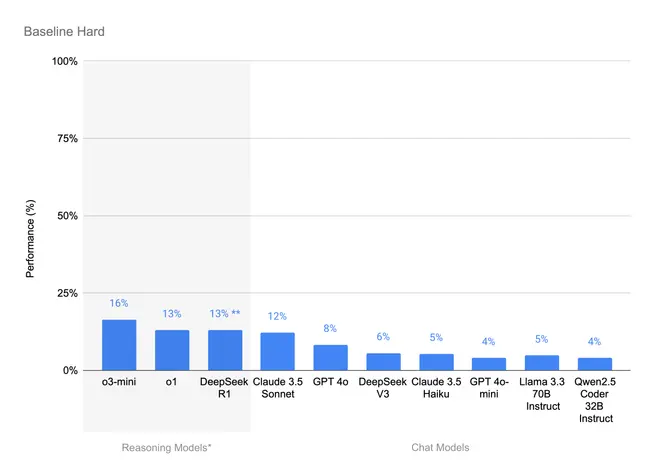
Figure 4: Performance (on Hard set) across closed and open models/providers. * The Reasoning Models did not work well on the unified ReAct prompt we were using across all chat models, so we had to craft a special Reasoning Prompt. See baseline implementation and prompt details here. We benchmarked the commercial offering of DeepSeek-V3
From Figure 4 we can see that there is a lot of progress to be made, even with the best agents available not crossing the 25% line.
The best performing agents were based on the latest reasoning models with o3-mini coming out on top at 16% accuracy and R1 coming in at 13%**. The closest chat-based model was Claude Sonnet at 12% the open DeepSeek V3 coming in at 6%.
One surprising finding was that while instruct models perform well out of the box with a ReAct prompt, reasoning models don’t and achieve 0% accuracy. Common failure modes include poor instruction following, invalid code syntax, closing code blocks (lack of), use tools (improper) and 1-turn dialogs (i.e., no sequential steps). It required multiple iterations on the prompt to get the reasoning models to perform well on this benchmark.
The baselines provided as part of the benchmark are standardized prompts across the chat and reasoning models, and thus, they should be considered non-optimized and a lower bound on performance.
Additionally, we tracked the cost to run the full benchmark for each commercial offering and compare them in Table 2 below:
o1
Cost
$435
Cost/Task
$0.967
Claude 3.5 Sonnet
Cost
$90
Cost/Task
$0.200
o3-mini
Cost
$85
Cost/Task
$0.198
GPT 4o
Cost
$50
Cost/Task
$0.111
Claude 3.5 Haiku
Cost
$35
Cost/Task
$35
GPT 4o-mini
Cost
$3
Cost/Task
$0.007
Deepseek V3
Cost
$2
Cost/Task
$0.004
Table 2: Costs for commercial models. Due to subjectivity/variance, we did not include price analysis of open models. Cost/Perf % is explored in Figure 5.
We break down the economics in Figure 5 by looking at the Accuracy vs Cost tradeoff.
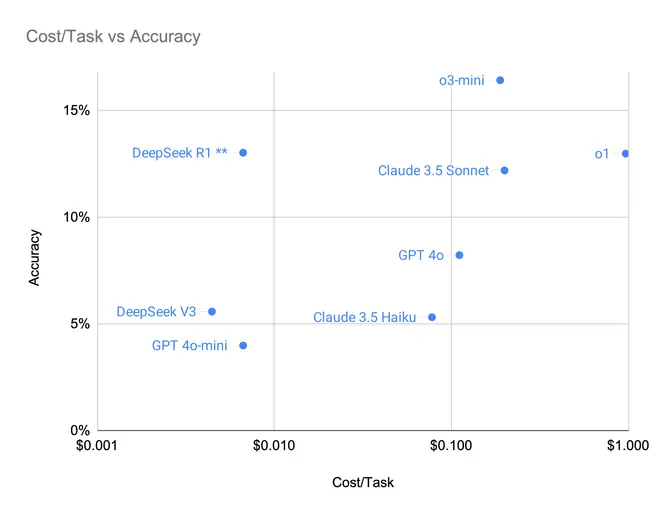
Figure 5: Performance and cost tradeoff between commercial providers.
Arguably, the economics of DeepSeek R1 are ideal as there is essentially no tradeoff between performance and cost.
Now, let’s have a look at how you can run these benchmarks yourself and evaluate your own models.
Getting Started and Infra
We are mindful that doing agentic research by interacting with the benchmark requires an execution environment (including GPUs) and involves costs. We are lowering the barrier by providing access to HuggingFace's Inference API and smolagents. With these tools, researchers get 1k free LLM requests daily and access to a secure local code execution environment.
For convenience, we provide an example notebook: a ready-to-go solution for submitting an entry at zero cost (quickstart.ipynb).
By eliminating friction, DABstep ensures that anyone, from seasoned researchers to curious newcomers, can contribute to advancing agentic workflows in data analysis.
Future direction
We are really excited about the release of DABstep and think it will help test the state of data analysis agents today. However, this release marks just the first step and we plan to evolve the benchmark over time.
At the rate of progress in AI, we foresee that the benchmark will eventually be considered solved in its current state. However, the benchmark is designed to be valid for a longer time by increasing the difficulty in many dimensions. We will be building on the benchmark with full backwards compatibility. Below are some broad avenues on which we will improve the baseline.
Tasks: The current tasks are very narrow and limited in scope, encompassing mostly fraud and payment fees. This is a subset of the real world, as there are many other dimensions and variables at play. In the future, we will expand the same benchmark, including tasks in the area of approval rates (issuer refusals), authentication drop-offs, and real-time situations over a wider time span such as seasonal components. This would test the capacity of agents to balance several variables at the same time and execute trade-offs on multiple dimensions.
Domains: The benchmark currently revolves around tasks from the financial sector. However, we invite researchers and practitioners from other fields, such as health, biology, insurance, telecommunication etc. to contribute new subsets to the benchmark so we can evaluate the performance across many domains.
Data scale: The structured data will eventually not be able to fit in memory. They will be analyzed with standard tooling, requiring the analysts to use distributed computing engines or scheduling workflows for later evaluation.
Documentation: The unstructured data that maps the domain knowledge will explode with more files containing time evolution (e.g., bulletins), different formats (e.g., PDF), and also different versions of similar but different logic that map each scheme, acquirer, or partner. The context will reach a step that will logically not fit the current and future token cardinality allowed in the context windows.
Multimodal: Agents should also become multimodal. To this end, we will enhance the benchmark with tasks that require extracting logic by interpreting and creating plots and graphs.
Related Works
Existing benchmarks for evaluating AI in data analysis have advanced the field and DABstep is built on top of their foundations.
DS Bench evaluates 466 questions from Modeloff competitions, primarily designed for Excel-based workflows. While effective for small-scale tasks, Excel does not support the iterative, code-driven workflows common in real-world data analysis (e.g., Jupyter notebooks). Additionally, reliance on GPT-4 as an evaluator introduces bias and reduces generalizability.
DS 1000 tests Python-based data analysis tasks sourced from StackOverflow, curated to avoid memorization. However, its tasks are short and single-shot, lacking real datasets and iterative reasoning. This limits its ability to evaluate end-to-end workflows or multimodal capabilities.
Acknowledgments: Harm de Vries (Graidd), Arjun Guha (Northeastern University), Hanna van der Vlis (Adyen).
References
* Tasks are realistic, the data has been generated synthetically. The business context (including merchant names, rates, volumes, transaction values, fraud rates, and fees) has been artificially generated and does not reflect the actual performance that businesses might exhibit. For example, fraud rates have been intentionally elevated for the purpose of this exercise.
**We had to design a special prompt for the reasoning models because our unified ReAct prompt, although performing excellently on chat models, performed exceptionally poorly on all the reasoning models.
*** R1 performance is extrapolated from a sample due to the prolonged outage at the time of this publication.