Report
Ottimizza i tassi di conversione e riduci al minimo il rischio di transazioni non andate a buon fine
Di Rodel van Rooijen, Data Scientist, Adyen

Forse ti sei imbattuto in situazioni in cui hai tentato di effettuare un pagamento, ma, per un motivo o per l'altro, non è andato a buon fine. Può essere una conseguenza frustrante, non solo per lo shopper, ma anche per il merchant.
Noi di Adyen studiamo bene questi casi. Infatti, una delle nostre principali priorità, in quanto azienda, è assicurarci che le procedure di pagamento si svolgano in maniera efficiente. Uno degli aspetti determinanti consiste nel monitoraggio e nell'ottimizzazione del tasso di conversione dei pagamenti, inteso come il rapporto tra i pagamenti avviati (tentativo di effettuare il pagamento avviato) e i pagamenti che hanno avuto esito positivo (il pagamento ha superato la procedura di autorizzazione).
Il problema
Le aziende che si avvalgono della nostra soluzione di pagamento si affidano automaticamente aRevenue Accelerate, un prodotto che ottimizza i tassi di conversione per loro conto. Nel contesto di questo prodotto, Adyen deve affrontare diverse scelte di fondo prima che un pagamento possa andare a buon fine. Ottimizzare il tasso di conversione implica una selezione fra le scelte che hanno la più alta probabilità di successo di un pagamento. Ne è un esempio la Strong Customer Authentication (SCA), ossia una procedura di autenticazione del cliente (ad esempio, mediante l'utilizzo dell'applicazione mobile di una banca) prima dell'effettuazione del pagamento. Per tutti i principalimetodi di pagamento(con carta), questa operazione passa attraverso una tecnologia chiamata 3D Secure (3DS). Alcune banche prevedono che tutti i clienti debbano autenticarsi prima che possa essere effettuato un pagamento, mentre altre potrebbero richiederlo solo per determinati importi. Altre banche invece potrebbero non essere in grado di supportare 3DS. Noi offriamo il nostro aiuto alle aziende sollevandole dalla responsabilità di decidere se richiedere o meno il 3DS. In questo scenario, RevenueAccelerate potrebbe ottimizzare il processo decisionale.
Il problema descritto finora sembra evidente. Siamo di fronte a due opzioni: far rispettare o meno la SCA. In realtà, però, potremmo ricorrere a molte altre ottimizzazioni. Ecco altri esempi di ottimizzazioni da noi applicate:
- Per il pagamento degli abbonamenti, richiedere l'aggiornamento di un conto (carta) dal sistema della carta e successivamente applicarlo.
- Ottimizzare la formattazione relativa al messaggio di pagamento (messaggio ISO). Ad esempio, le banche potrebbero scegliere di ricevere i campi in un determinato formato (nome del titolare della carta, campi dell'indirizzo e così via).
- Riprovare a effettuare un pagamento immediatamente, ad esempio quando il sistema di una banca risulta momentaneamente sovraccarico.
Nel complesso, tutto ciò comporta la possibilità di scegliere tra centinaia di ottimizzazioni. Tuttavia, partendo da questo insieme, come fa RevenueAccelerate a individuare le migliori ottimizzazioni?
La soluzione precedente
Siamo partiti con delle sperimentazioni (sotto forma di test A/B) per scegliere le giuste ottimizzazioni, che abbiamo perfezionato sulla base di due caratteristiche: il conto (ad es. per Spotify) e la banca (ad es. ING Bank N.V.).
Il risultato è stato un po' problematico:
- Problema a causa di un campione ridotto. L'aggiunta di ulteriori funzionalità di pagamento (ad esempio importo o tipo di transazione) può comportare la creazione di piccoli, e quindi insignificanti, gruppi di prova A/B.
- Sperimentazione contrapposta allo sfruttamento. Il risultato di un esperimento è deterministico, nel senso che se il contesto cambia, allora l'esperimento dovrebbe essere ripetuto nuovamente.
Inoltre...
Esistono molte soluzioni a un problema come quello sopra descritto. Nel nostro caso, abbiamo adottato un approccio (contestuale) Multi-Armed Bandit, e ciò per diversi motivi:
- Idealmente, risponde alle due problematiche che sono state affrontate.
- Il contesto (come le caratteristiche del pagamento) va tenuto in considerazione in maniera sostanziale, da qui l'aggiunta contestuale.
- Nonostante il mondo sia in costante mutamento, da un punto di vista tecnologico, un vero e proprio sistema di apprendimento per rinforzo appariva fuori portata.
Lo scenario può essere descritto al meglio come un'interazione ripetuta in più turni. Formalmente, a ogni turno:
- L'ambiente (cioè il mondo reale) rivela un contesto (cioè le caratteristiche del pagamento).
- Il discente sceglie un'azione (cioè un'ottimizzazione).
- L'ambiente rivela una ricompensa (ossia 0 per un pagamento non riuscito e 1 per un pagamento riuscito).
Scopo del discente è scegliere le azioni che massimizzano la sua ricompensa complessiva, ovvero la somma delle ricompense. Un esempio intuitivo consiste in un gioco basato su un'azione e una ricompensa (vincere o perdere). Un discente comincia a scegliere delle azioni. Dopo un po' di tempo, egli impara quali azioni portano a una vittoria, con la conseguenza che continuerà a scegliere solo quelle azioni. Nel nostro impiego, mediante l'interazione con il mondo reale, tentiamo di massimizzare il numero di autorizzazioni e, di conseguenza, il tasso di conversione dei pagamenti.
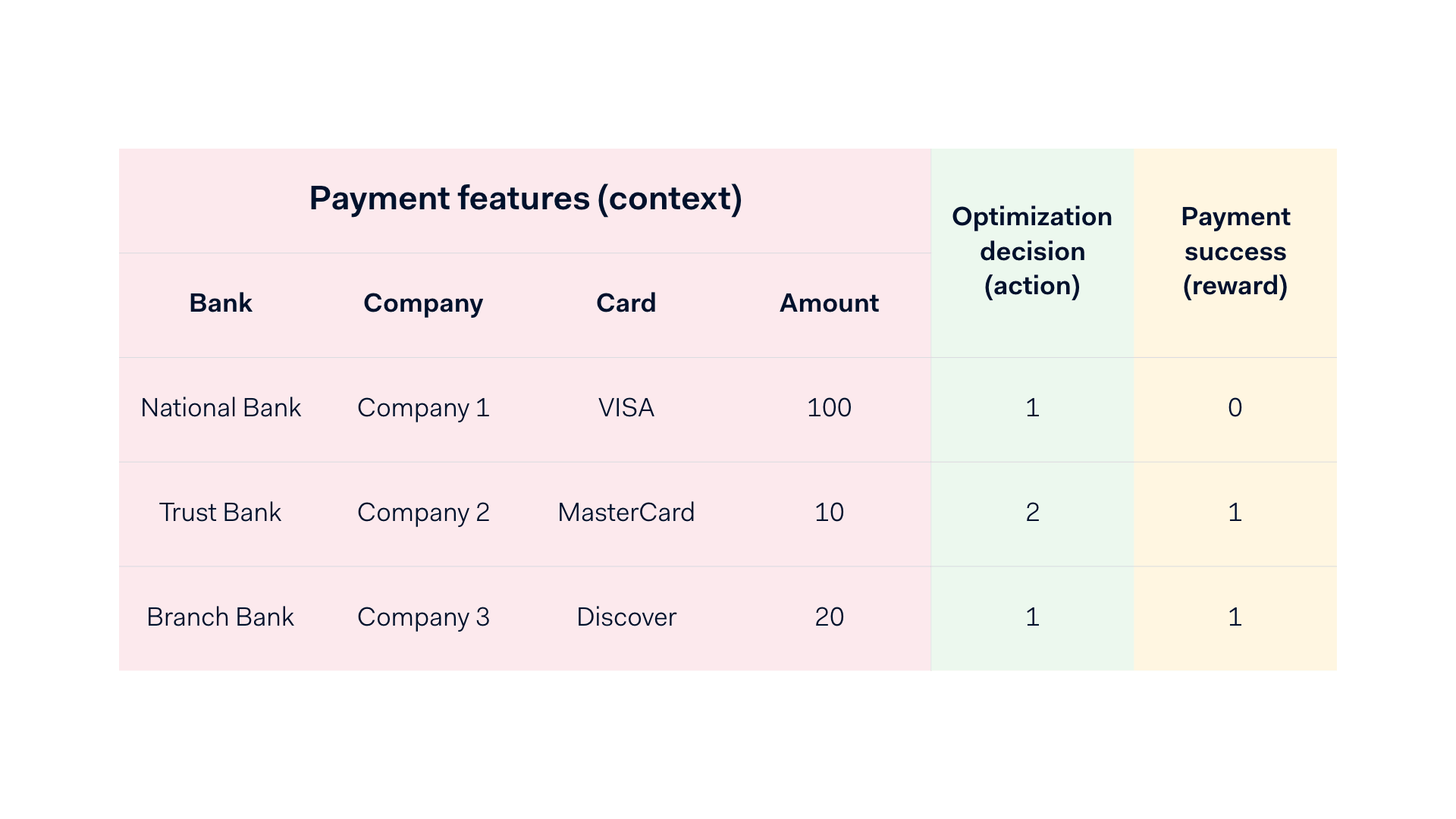
Un esempio del nostro ambiente con contesti, azioni e ricompense.
La nostra soluzione concettuale
Un classificatore in veste di oracolo
Al fine di poter definire le probabilità di successo per ciascuna ottimizzazione scelta, consideriamo la presenza di un oracolo. Impieghiamo questo elemento (inteso come una mappatura a partire dai contesti e dalle azioni fino alle probabilità) per fare una previsione circa le probabilità di autorizzazione. Per ricoprire il ruolo di oracolo sono stati presi in considerazione diversi modelli di classificazione, come ad esempio la logistic regression, random forest e i modelli di gradient boosting.
Alla fine, si è scelto di adottare un'implementazione specifica di modelli di gradient boosting, ovvero XGBoost (eXtreme Gradient Boosting). Le ragioni di questa scelta sono state svariate e quelle più importanti prendono in considerazione la dimensione del model artifact (di cui ci occuperemo più avanti), così come le prestazioni del classificatore in termini di area sottesa alla curva ROC (AUC) e Area Under the Precision-Recall Curve (AUCPR).
Caratteristiche del modello
- Una serie di funzioni numeriche, ad esempio l'importo convertito in EUR, la data di scadenza in giorni della carta delta (compresa tra la data di pagamento e la data di scadenza).
- Una vasta selezione di caratteristiche di categoria (ad es. tipo di carta, banca, azienda, ecc.) per le quali abbiamo adottato la codifica Target Encoding (ad esempio, qual è stato il tasso di conversione per un determinato valore di categoria?)
- Ciascuna decisione di ottimizzazione ha una propria caratteristica fittizia, nel senso che ogni ottimizzazione presenta una funzione di zero o una che indica se è stata applicata su un pagamento. Da notare che ciascuna delle combinazioni di ottimizzazione è considerata come un'unica azione.
Avvalendosi dei dati storici, l'oracolo può imparare a calcolare la probabilità di successo sulla base dei risultati precedenti. Esistono però alcune insidie. Innanzitutto, esiste un pregiudizio nella scelta, dal momento che le azioni selezionate in passato potrebbero essere scelte in modo parziale (ad esempio attraverso la scelta di una sola azione e la rinuncia all'esplorazione delle altre opzioni). Questa condizione comporta anche il rischio che alcune azioni non siano mai state osservate, il che rende problematica l'inferenza per queste azioni. Inoltre, la situazione di fondo potrebbe trasformarsi da un momento all'altro (ad esempio, una banca potrebbe sostituire il proprio sistema antifrode e bloccare improvvisamente i pagamenti già effettuati con successo), vanificando così l'implicazione storica. Infine, se il modello non è ben allineato, le probabilità rischiano di non avere alcun senso.
La linea di condotta per la selezione delle azioni
Per giustificare quanto sopra, sfruttiamo uno dei principi fondamentali del problema dei banditi a nostro vantaggio. Si tratta di esplorare e sfruttare determinate azioni. Nel momento in cui il modello è certo dell'azione migliore, dovremmo approfittarne. Se il modello risulta essere incerto, dovremmo approfondire ulteriormente la ricerca. Ne risulta una linea di condotta che determina una mappatura tra situazioni e azioni.
La nostra linea di condotta è strutturata nel modo seguente:
- L'azione migliore viene selezionata secondo il metodo epsilon-greedy, vale a dire che il rapporto delle "ottimizzazioni migliori" (utilizzo) è impostato su una percentuale fissa α. Nel corso del tempo, tale percentuale può essere aumentata o diminuita in base alle prestazioni rilevate.
- Riguardo alla percentuale rimanente di 1-α, scegliamo un'azione dal resto dell'insieme di possibili ottimizzazioni (esplorazione). Per modulare le probabilità residue, usiamo una funzione softmax che converte le probabilità di successo in probabilità bilanciate/normalizzate dalle quali selezionare le azioni.
- Alla fine, ne derivano delle probabilità per azione che equivalgono a 1. L'azione conclusiva viene quindi scelta in modo casuale usando queste probabilità bilanciate/normalizzate come parametri di peso.
Durante l'addestramento del modello, si prendono le probabilità normalizzate (cioè i valori ponderati) valutando le osservazioni a campione e ponderandole in base al valore inverso della probabilità dell'azione che è stata intrapresa. Nell'esempio che segue, il modello restituisce la probabilità dell'oracolo, che determina una probabilità di azione normalizzata dopo l'applicazione di una determinata policy. Infine, i pesi campione vengono dedotti in quanto rappresentano l'inverso della probabilità d'azione, e vengono poi reintrodotti nel'addestramento del modello. Questa procedura genera un ciclo di feedback con la stessa frequenza di ogni riconfigurazione del modello.
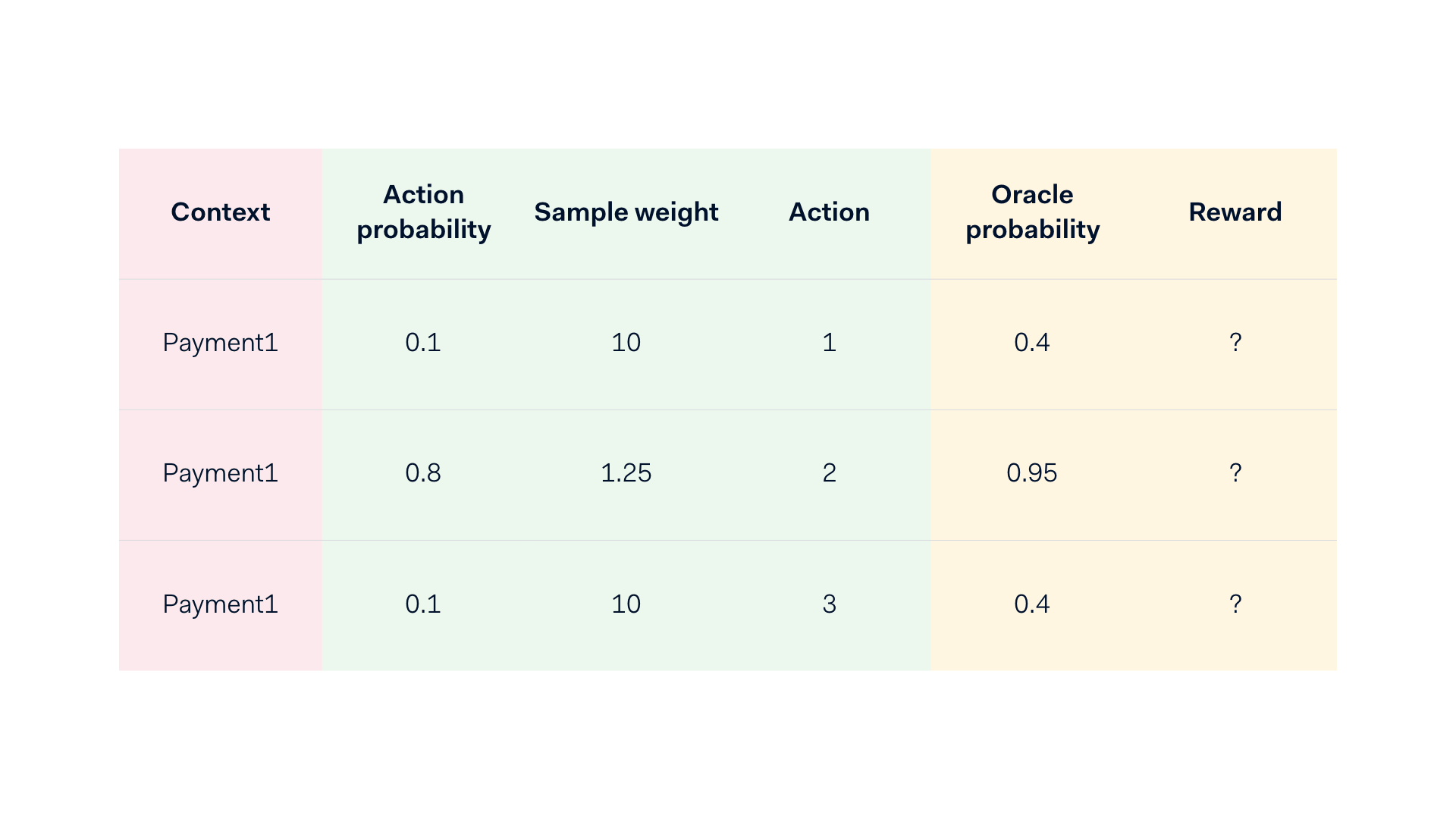
Un esempio di contesto "esploso" caratterizzato da azioni e interventi possibili contrapposti alle probabilità dell'oracolo.
La soluzione tecnica
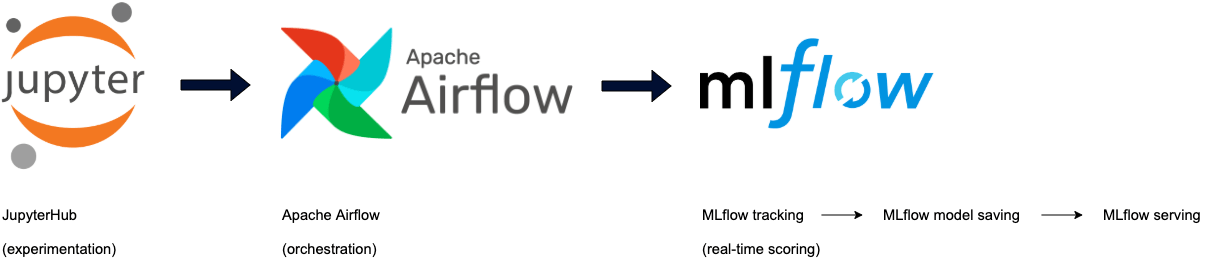
La sfida più importante è stata di introdurre la soluzione concettuale in un ambiente di produzione. Infatti, per Adyen si è trattato di un primo tentativo per mettere in produzione una macchina per l'apprendimento a bassa latenza.
Sperimentazione
Durante la sperimentazione, il nostro team ha fatto leva sui notebook di Jupyter. Queste applicazioni sono gestite su un cluster di dati centralizzato, il che rende le iterazioni dei modelli facili e veloci. Nel momento in cui un modello è pronto per essere distribuito o per essere sottoposto a ulteriori sperimentazioni, il codice è affidato al repository del codice, in cui le classi del modello sono definite con i propri test e la propria orchestrazione.
Orchestrazione
L'orchestrazione della messa a punto dei modelli (insieme alla regolazione dell'iperparametro) avviene attraverso un DAG di Apache Airflow programmato, che prepara i modelli con una frequenza costante e li rende automaticamente disponibili in un archivio di modelli di artefatti. Utilizziamo MLFlow sia per salvare i nostri modelli che per monitorarne le metriche che si sono dimostrate rilevanti durante la fase di preparazione. MLFlow consente di salvare il modello in formato Python, il che ci permette di integrare il meccanismo di selezione delle azioni (la policy/linea di condotta) direttamente nel metodo di "previsione".
Valutazione in tempo reale
In questo contesto accade qualcosa di magico che merita sicuramente un post nel blog. Per rendere possibile la valutazione dei modelli a bassa latenza, disponiamo di attrezzature dedicate che si occupano solo di ospitare i nostri modelli. Per far funzionare il tutto, utilizziamo diverse tecnologie, di cui non ci occuperemo in questo blog. In definitiva, MLFlow è il fattore principale alla base della realizzazione del ciclo completo (cioè il salvataggio, il caricamento e la previsione).
Abbiamo affrontato alcuni problemi specifici legati ai modelli. Uno degli inconvenienti principali che ci siamo trovati ad affrontare riguardava le dimensioni del modello di artefatto, dal momento che sui server tale modello viene mantenuto in memoria per garantire previsioni a bassa latenza. Ad esempio, ciò comporta dei problemi quando si cerca di preparare un grosso modello di foresta casuale. Un modello del genere può produrre un oggetto modello che ha un valore di (diversi) gigabyte di dati, una volta salvato.
Un altro problema consisteva nel porre un freno alla dipendenza con il nostro codebase. Lo scopo era di avere una dipendenza minima dai pacchetti necessari per far funzionare il modello (o i modelli). Questa soluzione è stata raggiunta salvando il codice specifico del modello (ad es. alimentatori, estimatori e oggetti di valutazione) insieme allo stesso modello.
Risultati
Il confronto tra la soluzione precedente e quella nuova costituisce la parte principale dei risultati. Paradossalmente, siamo tornati alla configurazione di prova A/B per confrontare la vecchia soluzione con la nuova. Le misurazioni sono state effettuate in un periodo di circa 2 mesi, con frequenze settimanali di riconfigurazione (e valutazione delle linee guida). Nei risultati porremo in evidenza due casi: i) una società di e-commerce nel settore delle telecomunicazioni; e ii) un'azienda di servizi di streaming.
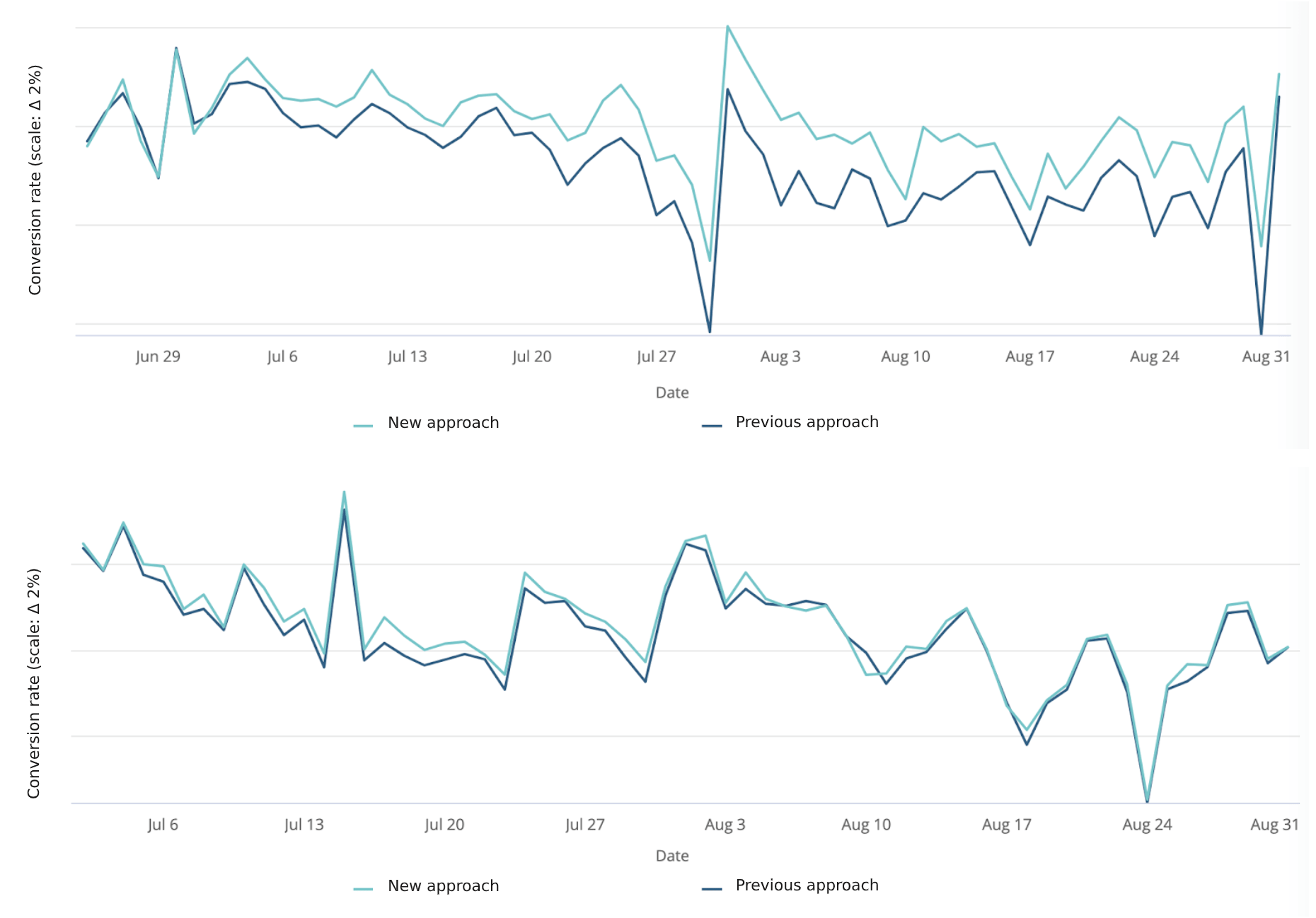
Tassi di conversione
Come illustrato in precedenza, la soluzione richiede del tempo per migliorare le sue prestazioni, ma, a quanto pare, dopo un po', inizia a superare le aspettative. Nel secondo esempio, le prestazioni sembrerebbero variare nel corso del tempo. La causa principale è da ricercarsi nei cambiamenti del mondo reale. Non appena il modello viene nuovamente preparato e la linea di condotta viene riesaminata, i guadagni in termini di rendimento diventano maggiormente visibili. Probabilmente, una soluzione complementare per l'apprendimento capirebbe questi cambiamenti più velocemente.
Conclusione
Noi di Adyen analizziamo con attenzione i nostri tassi di conversione dei pagamenti. Infatti, grazie a una conversione dei pagamenti quanto più possibile ottimizzata, semplifichiamo le procedure di pagamento, aumentando al tempo stesso il fatturato delle aziende che utilizzano Adyen in tutto il mondo. In questo blog abbiamo ripercorso le modalità di progettazione, realizzazione e implementazione di una infrastruttura per l'apprendimento automatico a bassa latenza al fine di aumentare i tassi di conversione dei pagamenti.
Carriere Tech in Adyen
Siamo alla ricerca di ingegneri e tecnici di talento per aiutarci a costruire le infrastrutture del commercio globale!
Controlla le offerte di lavoro per sviluppatori